
Milvus 集群线上问题记录
问题现象
下午 2点多,突然线上Milvus集群全部崩溃了,具体表现如下:
- 大量Node OOM
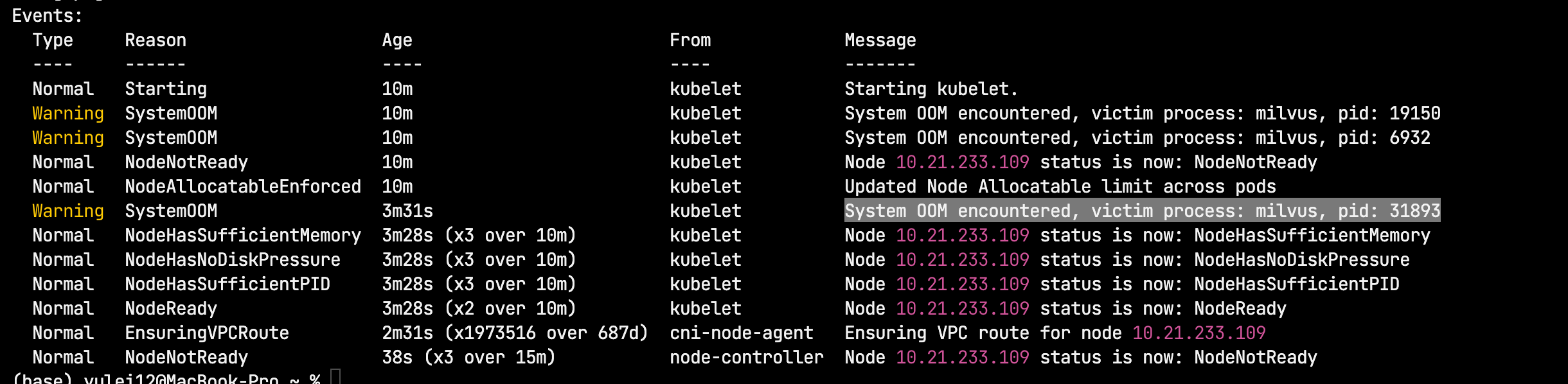
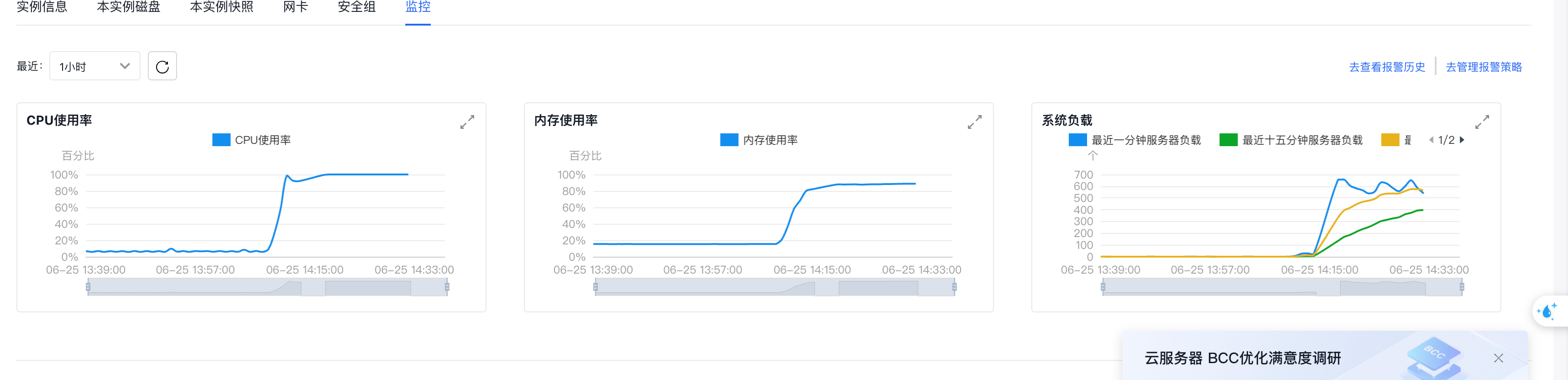
- 机器负载本不高,但1-2分钟内cpu、内存、负载全部被打满
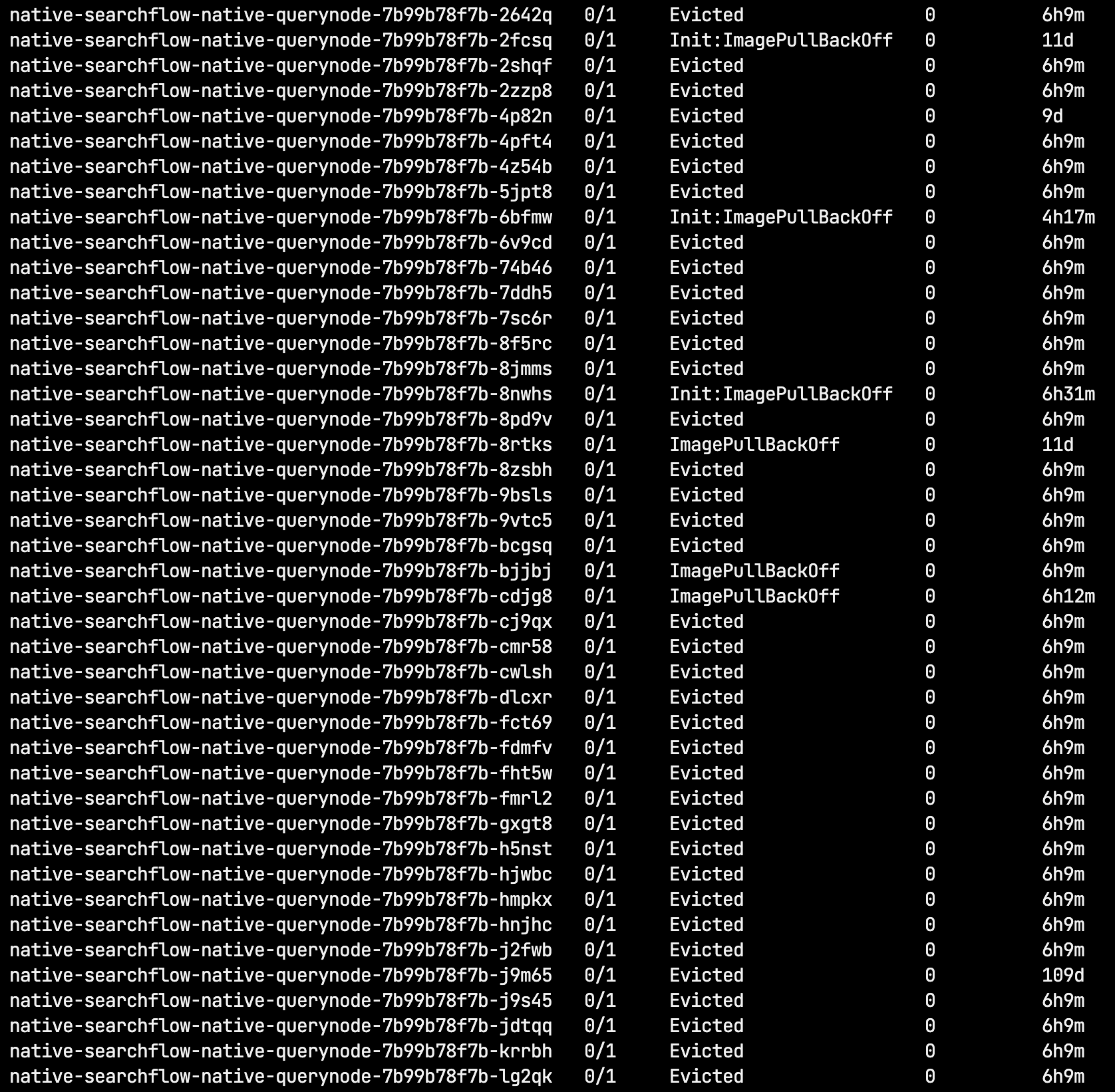
- querynode 大批量被驱逐
- 多个 Namespace 下的服务均不可用,均受到影响
问题排查
监控如下:
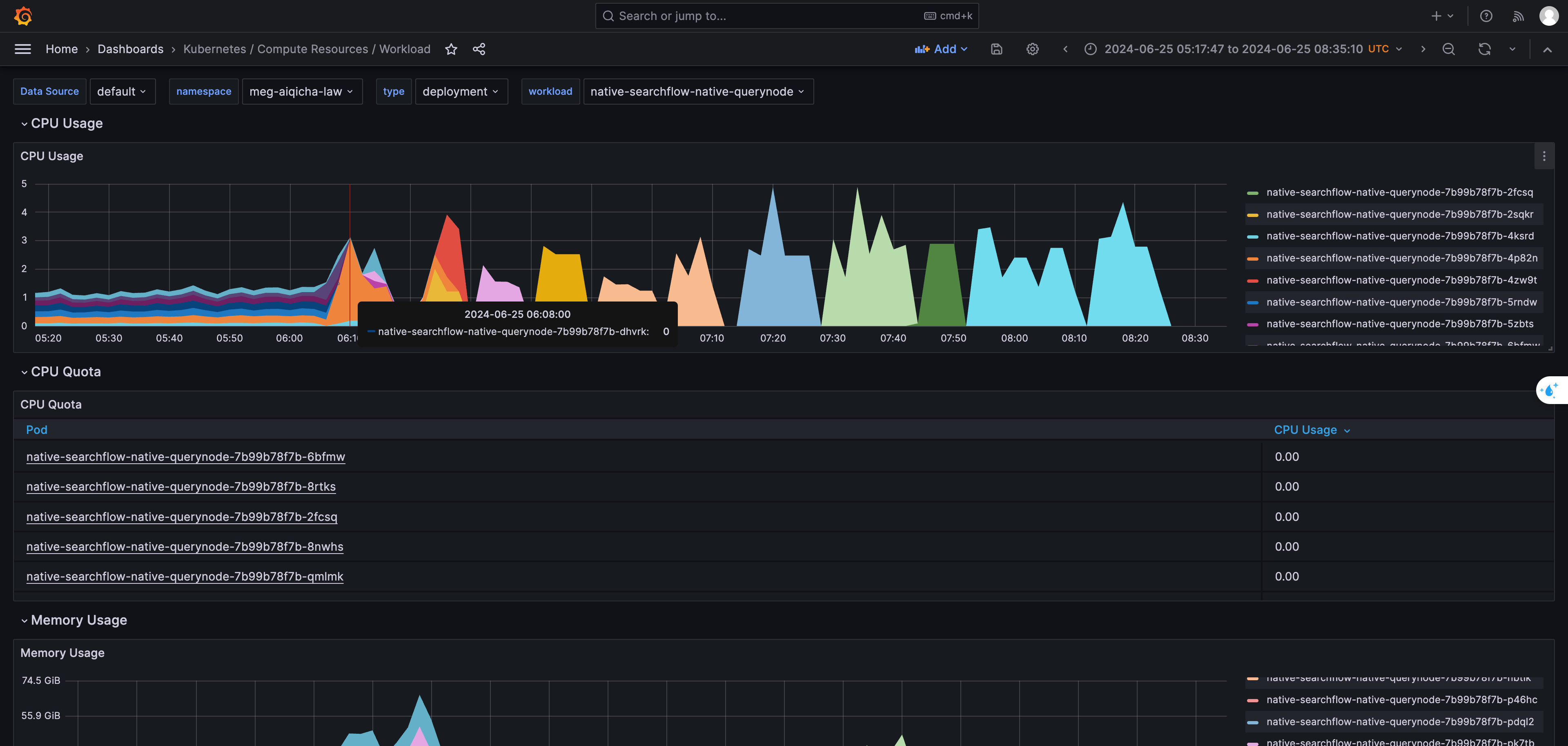

初步原因定位是对单个 querynode 的压力,超过了集群物理机所能负载的上限,正常情况下querynode 崩溃,会在其他物理机上重建,具有自恢复能力,问题时间段,有一个querynode一直在重建,但是负载太高了,每次重建物理机的资源都不够,所以一直在不同的物理机上一直重建,造成多台物理机OOM,造成集群崩溃
解决方案
根本解决方案:
原有机器为 4C16G 配置,新扩容 多台 8C32G 配置,解决问题。
实际操作:
- 扩容多台 8C32G 物理机
- 标记 OOM 节点为不可调度
kubectl cordon <node-name>
- 驱逐 OOM 节点上的 pod 到新集群
kubectl drain <node-name> --ignore-daemonsets --delete-emptydir-data

