Milvus 多租户方案选型
方案选型
在 milvus 中实现多租户方案,有以下几个备选方案
| 方案 | 方案名称 | 方案详细设计 | 优点 | 缺点 |
|---|---|---|---|---|
| A | 一个集合用于所有租户 | 使用单个集合通过添加租户字段来区分租户来实现多租户是比较简单的。对特定租户进行 ANN 搜索时,使用 expr 过滤掉其他租户的数据。这是实现多租户的最简单方法。 | 1. 实现最简单 2. 可以实现无限租户 | 1. 过滤器的性能可能会成为 ANN 搜索的瓶颈 2. 数据隔离性查,没有物理区分 3. 集合每次查询都需要查询全部数据,内存使用大、查询速度慢 |
| B | 每个租户一个集合 | 为每个租户创建一个集合来存储自己的数据,而不是将所有租户的数据存储在单个集合中。 | 1. 拥有非常快的查询速度 2. 数据隔离性好 | 1. 租户数量超过单个 Milvus 集群支持的最大集合数,则会遇到问题,最多 65536 个集合 2. 租户多了需要在资源调度、运营能力和成本方面投入更多 |
| C | 每个租户一个分区(V1 版本) | 管理单个集合比管理多个集合要容易得多。请考虑为每个租户分配一个分区,以实现灵活的数据隔离和内存管理,而不是创建多个集合。面向分区的多租户的搜索性能比面向集合的多租户要好得多。 | 1. 拥有较快的查询速度 2. 数据隔离性好 | 1. 租户数量超过单个集合的最大分区数,则会遇到问题,最多 4096 个分区 2. 管理方便 |
| D | 基于分区键的多租户 | 创建集合后,指定租户字段并将其设置为分区键字段。Milvus 将根据分区键字段中的值将实体存储在分区中。在进行 ANN 搜索时,Milvus 会根据指定的分区键切换到分区,根据分区键筛选实体,并在过滤后的实体中进行搜索。 | 1. 拥有较快的查询速度 2. 数据隔离性较好 | 1. 可以在内存、速度损失较少的情况下实现无限租户 2. 管理较为方便 |
评价原则
- 为支持日后的发展,方案需要支持未来海量租户的需求,方案 AD 可以实现
- 应该有较好的数据隔离,方案 BCD 可实现
- 需要有比较好的查询性能,方案 BCD 可实现
选型结果
选择了方案 D,是 milvus 最新支持的 基于分区键的多租户
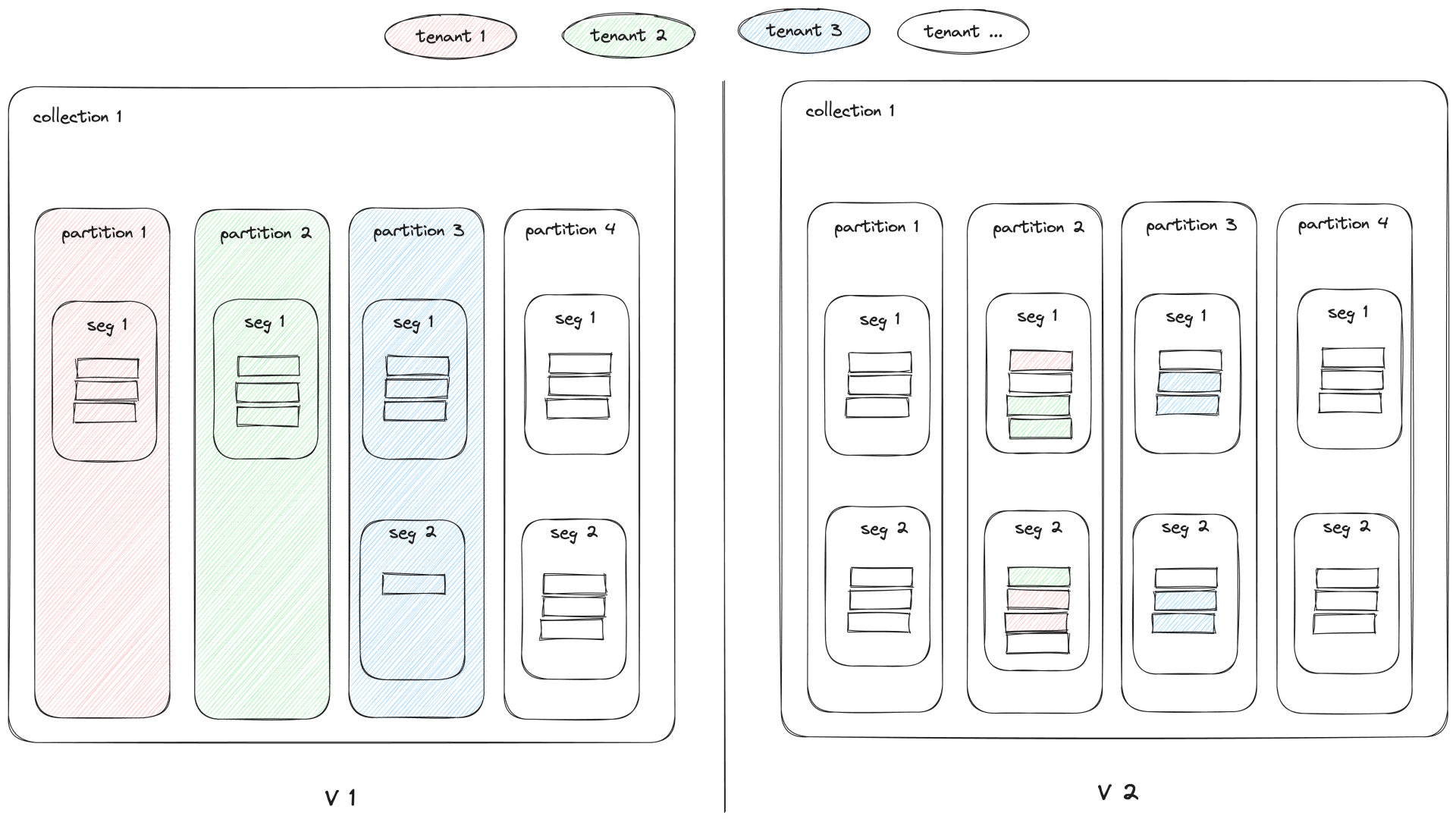
方案 C(V1)、D(V2)实现多租户的对比
数据变分散
- 每个租户一个 partition ,无法支持万级别租户的查询实现(最多 4096 个租户)
- 每个租户使用一个 partition-key ,经 hash 后多个租户使用一个 partition,支持万级别的租户查询
- 使用 partition-key 进行租户隔离的情况下,在查询 segment 时,会扫描其他用户的数据,意味着需要加载到内存的数据量变大且执行查询的 querynode 节点会变多,内存消耗会有所增长
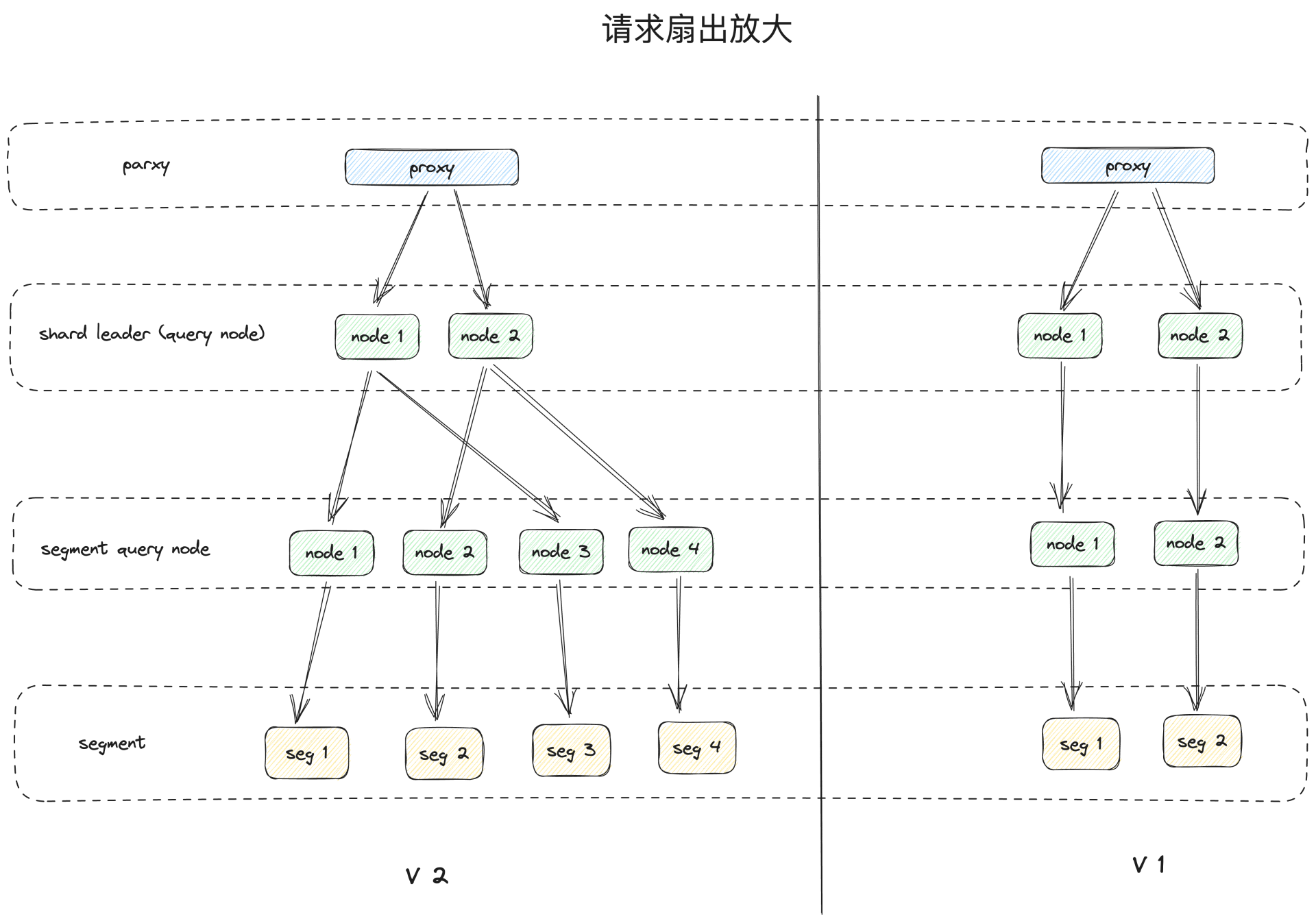
请求扇出放大
- v1 版本同租户的请求存放在同一 partition 内,所以数据存放紧密,分段少,请求扇出较少
- v2 版本不同租户的数据混合存放,会造成单个请求的扇出会放大,同时多个租户的请求扇出会同时放大,增大系统压力
- 解决方案:未来会聚合压缩离散程度较大的大租户数据,修改 partition-key Hash 表数据,减少扇出造成的压力;
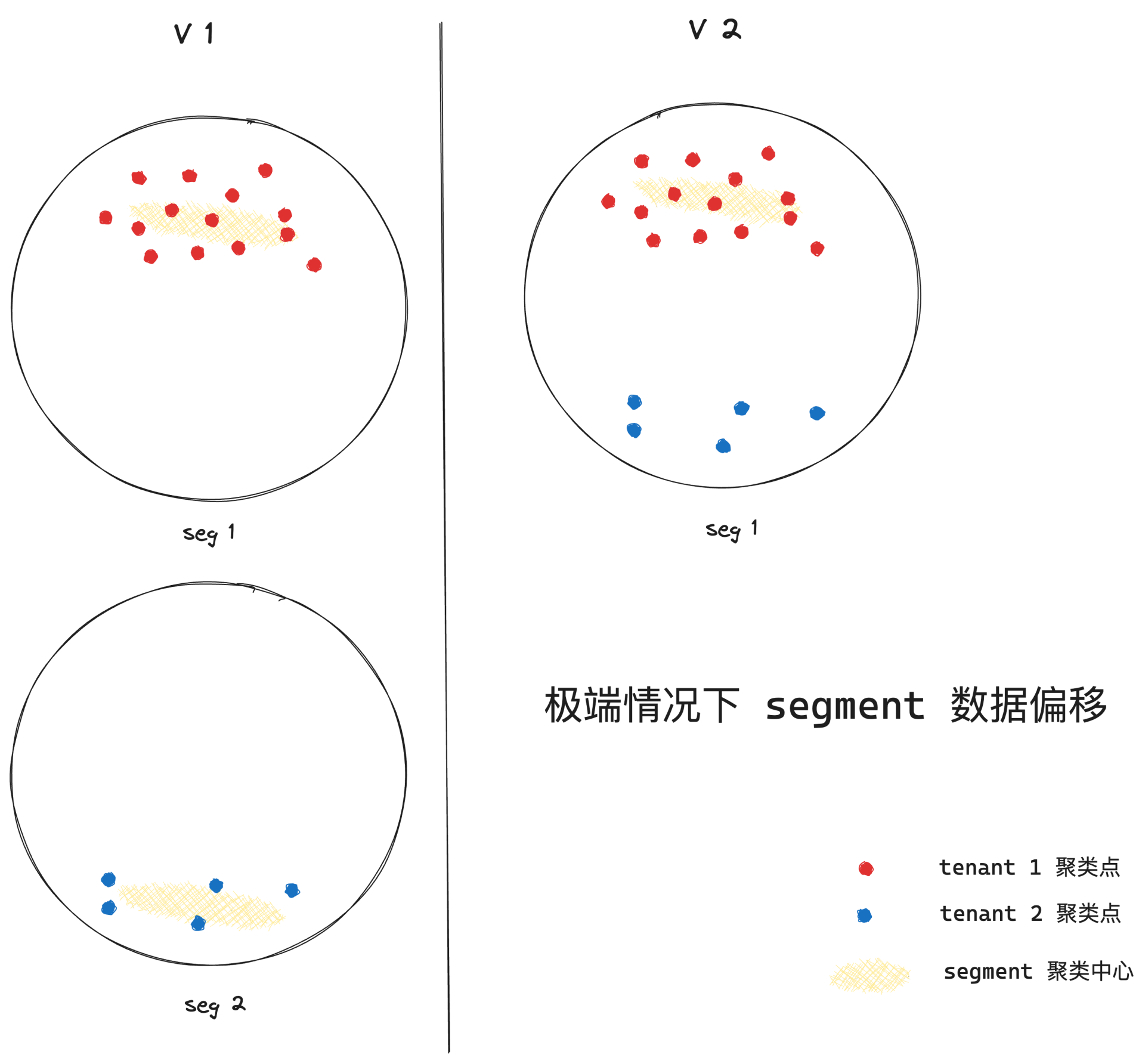
极端情况下的数据偏移
- 不同租户的数据可能会存在聚类中心不一致的情况
- v1 版本由于并不存储在一个 segment 下,所以不存在问题
- v2 版本可能不同租户的数据会存放在同一个 segment 下,那存储数量少的租户数据离聚类中心的距离就会变大,可能会造成检索速度下降或者 distance 计算不准导致的准召下降
- 解决方法:经过离散程度较大的大租户数据压缩后,独立训练被压缩数据的聚类中心和索引;
额外补充
milvus segment 查询方式