
一、向量 Vector & Embeddings
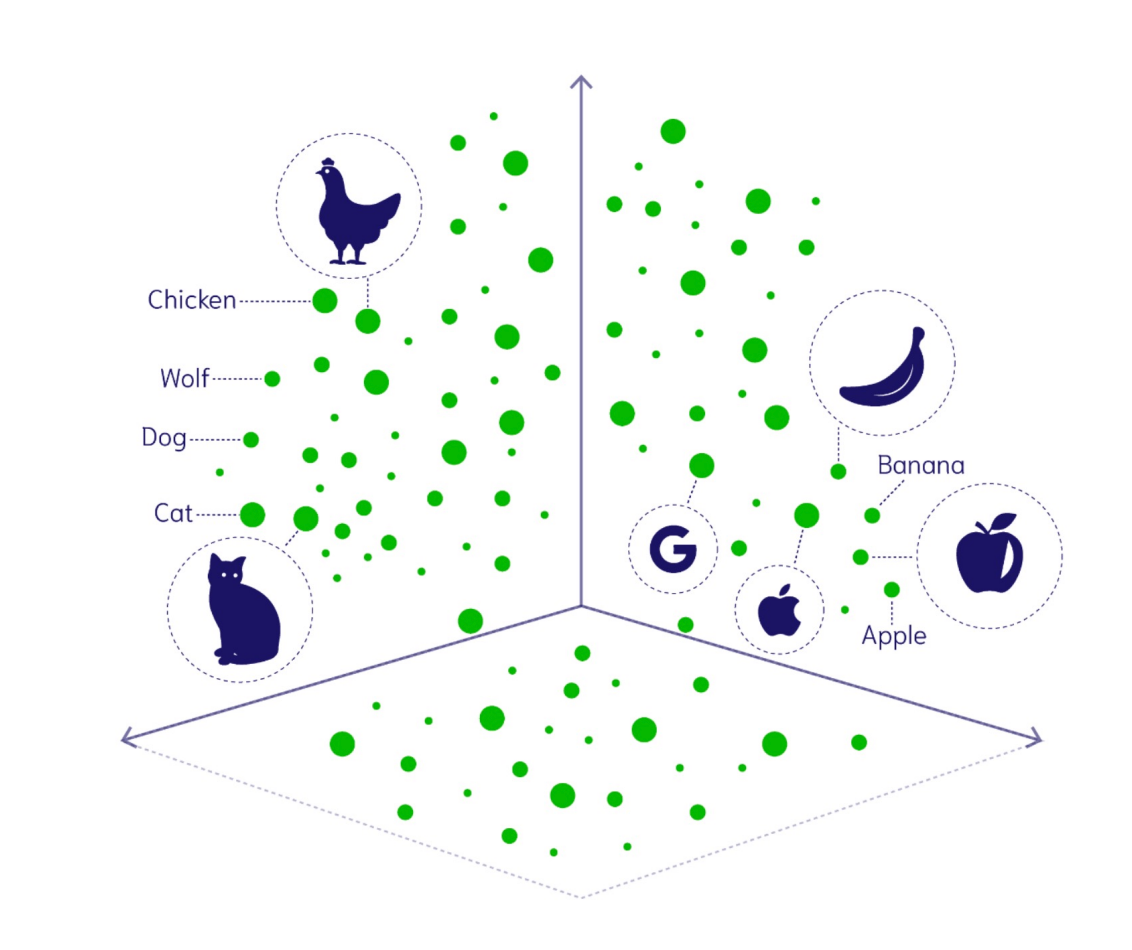
1.1 什么是向量?
在数学和计算机领域,向量有着不同的含义
==数学概念——Vector(向量)==
- 数学上的通用概念,是一个有方向和大小的实体,可以在几何空间中表示,也可以是一个 n 维的数值序列。
- 形式:向量通常如下图所示 ,可以表示几何点、物理量(如速度、力)或者任意数据序列。
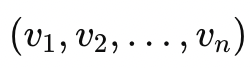
- 应用广泛,例如物理(速度、加速度等)和数学计算。
==计算机概念——Embeddings(嵌入)==
- 是一个特定领域的概念,指的是将高维或复杂结构的数据映射到低维向量空间中,同时尽可能保留数据的原始特征或语义关系。
- 常用于自然语言处理(NLP)和机器学习领域,将文本、图像或其他高维对象表示为向量,便于计算和分析。
- 通常通过机器学习模型训练得到。
- 举例:为了描述人,我们可以通过
[身高,体重,性别]来提取一个人特征
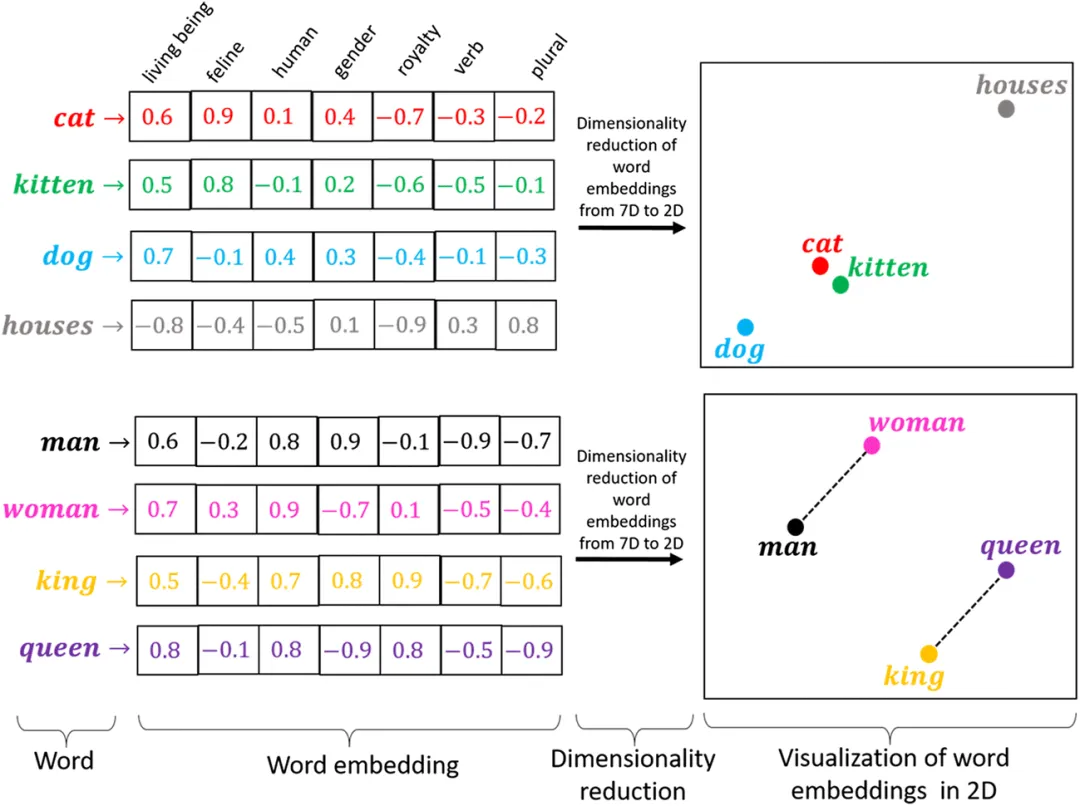
注:一般描述一个 embeddings 时,我们要明白他代表的是一个数据的特征,当我们作图表示这个 embeddings 时,一般采用数学上的定义,定义为有方向和大小的实体,而且一般是用 2 维或者 3 维来表示,尽管这个embeddings 可能是 768 维的,因为人无法想象超过 3 维的概念。
==向量:AI 时代的数据交换“新标准”==
随着 AI 技术的不断发展,向量正在逐步崭露头角,成为 AI 时代潜在的“数据交换标准”,就像互联网时代广泛使用的 JSON(JavaScript Object Notation)一样。
- 数据表示在 AI 领域,各种类型的数据(包括文本、图像、声音等)常被转换成向量形式,以便后续的处理和分析。
- 特征提取向量中的每个元素通常代表数据的一项特征。例如在图像中可对应像素强度,在文本中可对应语义属性。
- 模型参数在机器学习过程中,模型的参数(如权重、偏差)多以向量形式表示,并通过各种优化算法来进行迭代训练。
- 有序性向量中的元素以固定顺序排列,每个位置对应一个特定维度,保证了数据结构的有序性。
- 可运算性向量可以进行加法、减法、点积等数学运算,这些运算在 AI 算法中被广泛应用,便于快速处理和计算。
- 多维度向量的维度(即元素数量)可根据具体任务和数据类型而变化,可能是二维、三维,也可能是数百乃至数千维度。
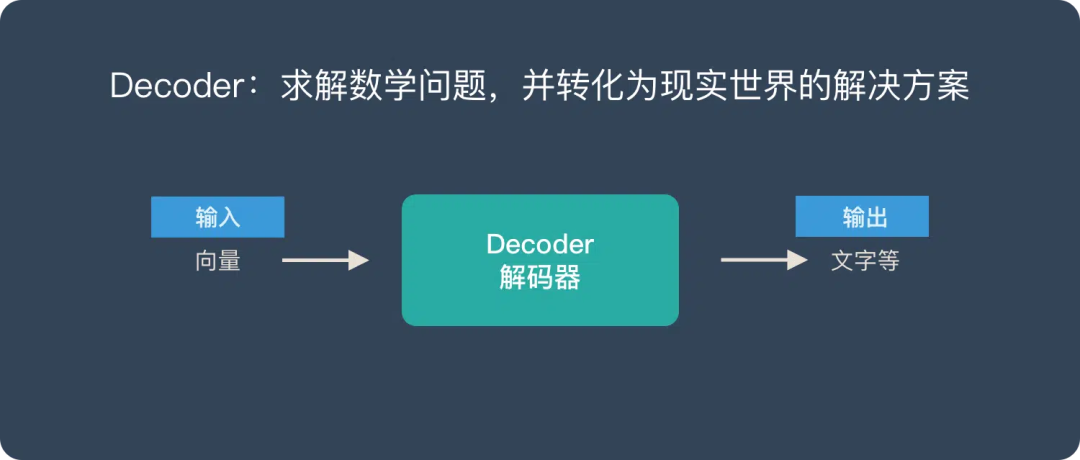
==向量是Encoder-Decoder的桥梁:将现实问题转化为数学问题,通过求解数学问题来得到现实世界的解决方案。==
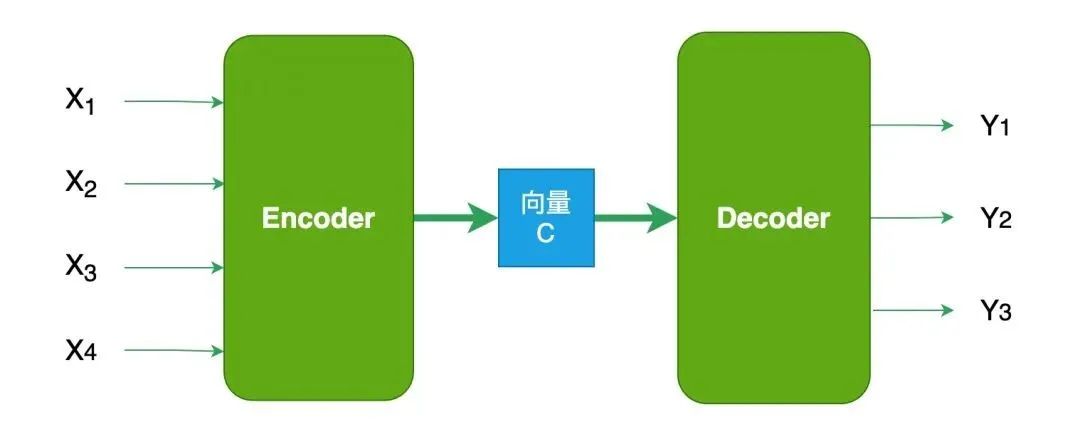
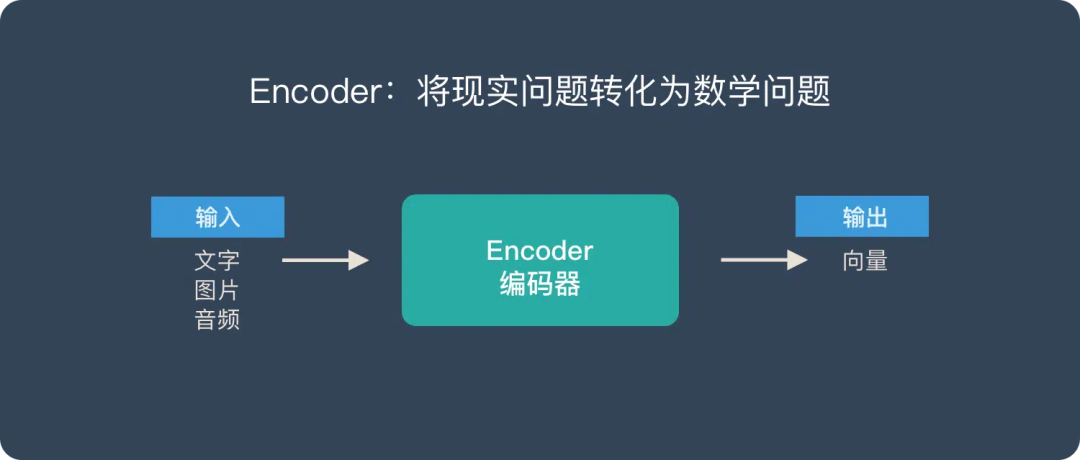
- Encoder (编码器) “将现实问题转化为数学问题”
- Decoder (解码器) “求解数学问题,并转化为现实世界的解决方案”
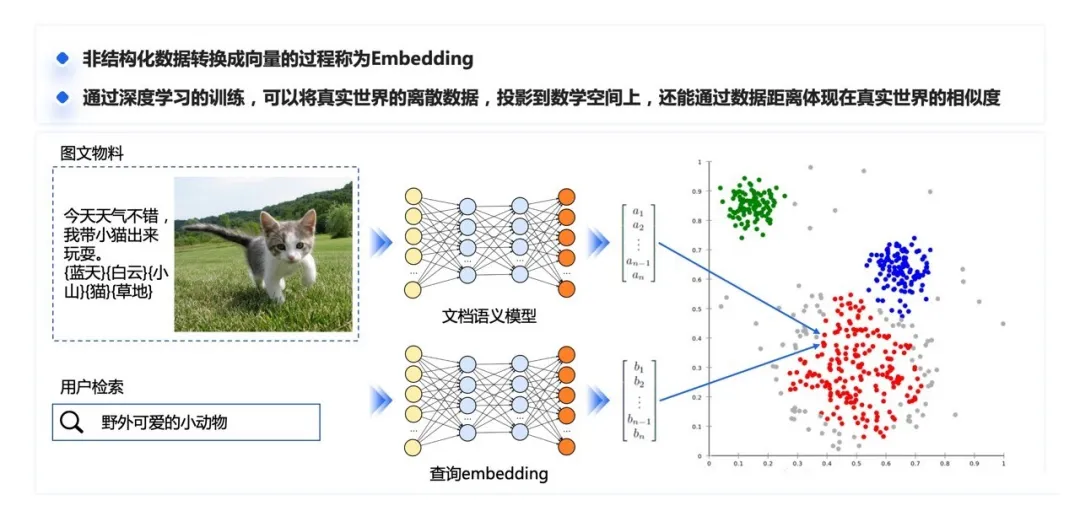
1.2 向量转换过程(Embedding)
非结构化数据转换成向量的过程称为 Embedding(嵌入)。通过深度学习的训练,可以将真实世界数字化后的离散特征提取出来,投影到数学空间上,成为一个数学意义上的向量,同时很神奇的保留着通过向量之间的距离表示语义相似度的能力。

1.2.1 文本向量化(Text Embedding)
将文本数据(词、句子、文档)表示成向量的方法。
词向量化
将单个词转换为数值向量
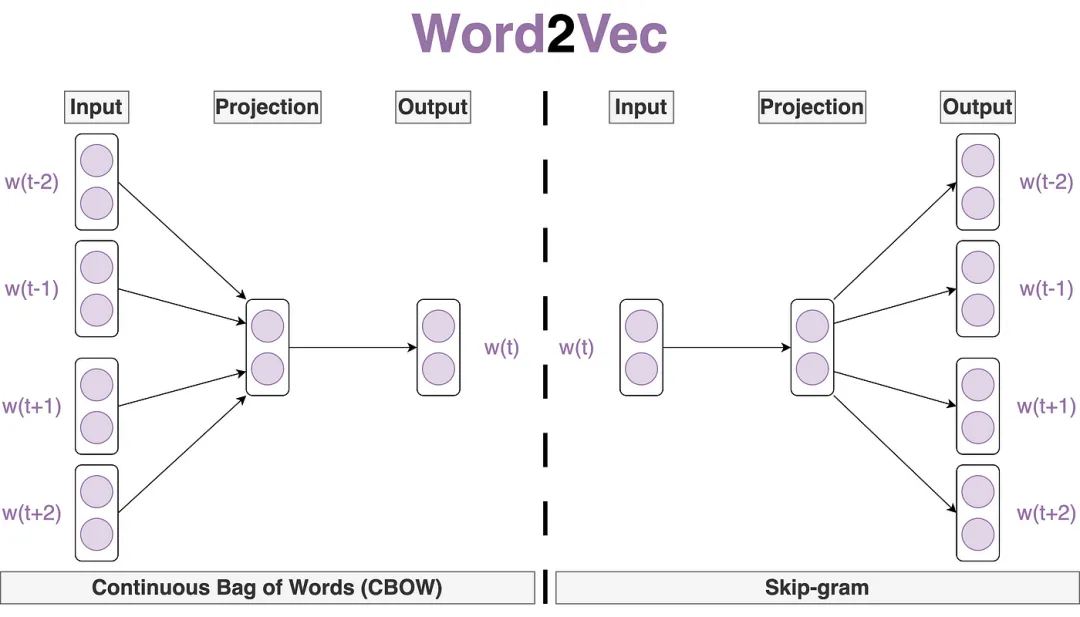
Word2Vec:一种捕捉单词语义与语法关系的词向量化技术
Word2Vec 是一项广为人知的 Word Embedding(词向量化)技术,用于将单词表示为高维空间中的密集向量,从而捕捉单词之间的语义和语法关系。它主要包括以下两种模型:
-
Skip-Gram(跳字模型)
-
核心思路:通过给定的“中心词”来预测其上下文中的单词。
-
工作方式:对于文本中的每个单词,Skip-Gram 模型将其视作中心词,并尝试预测一定窗口大小内出现的其他单词(即上下文单词)。
-
形象比喻:好比一个“词汇侦探”,利用中心词这一“线索”,去“追踪”并预测周围的单词,从而构建词汇间的语义关联。
-
-
CBOW(Continuous Bag of Words,连续词袋模型)
-
核心思路:与 Skip-Gram 相反,CBOW 模型通过给定的“上下文单词”来预测中心词。
-
工作方式:对于文本中的每个中心词,CBOW 模型会将其周围一定窗口大小内的其他单词(即上下文单词)作为输入,并尝试预测该中心词。
-
特点:通过聚合周围词的信息,逆向推断中心词的特征,实现词向量的学习。
-
这两种模型各有侧重,Skip-Gram 更适用于语料规模较大、关注低频词的情况,而 CBOW 在处理速度和计算效率方面更具优势。通过 Word2Vec,我们不仅能获取单词之间更丰富、更细致的语义关系,也能为后续的自然语言处理任务(如文本分类、情感分析等)提供更有力的支持。
句子向量化
将整句话转换为一个数值向量。相比仅对单词进行向量化,句子向量化能够更全面地表示句子的整体语义和语法信息,因而在语义搜索、情感分析、机器翻译等任务中都至关重要。常见的方法包括:
- 简单平均/加权平均
- 做法:对句子中每个单词的词向量进行平均,或根据单词频率进行加权平均。
- 特点:实现简单、计算量小,但无法充分捕捉单词在句子中的顺序和相互依赖关系。
- 递归神经网络(RNN)
- 做法:通过循环或递归地处理句子中的每个词,将前面词的表示与当前词进行合并,逐步生成句子表示。
- 优点:适合处理序列数据,能在一定程度上捕捉上下文依赖。
- 示例:LSTM、GRU 等变体在长句子或复杂依赖关系的表征上有更好的效果。
- 卷积神经网络(CNN)
- 做法:利用卷积层对句子进行局部特征提取,随后经过池化等操作得到整体句子表示。
- 优点:在提取局部特征、识别关键信息方面表现较好,同时具有并行计算的优势。
- 适用场景:常用于句子分类、文本情感分析等任务。
- 自注意力机制(如 Transformer)
- 做法:典型代表是 BERT、GPT 系列等模型,通过自注意力机制对句子中每个词与其他词的关系进行加权计算,从而生成包含全局信息的句子表示。
- 优点:擅长捕捉长距离依赖,平行化效果好,已成为当前自然语言处理中的主流方法。
文档向量化
将整个文档(如一篇文章或一组句子)转换为一个数值向量。
- 简单平均/加权平均:对文档中的句子向量进行平均或加权平均。
- 层次化模型:如Doc2Vec,它扩展了Word2Vec,可以生成整个文档的向量表
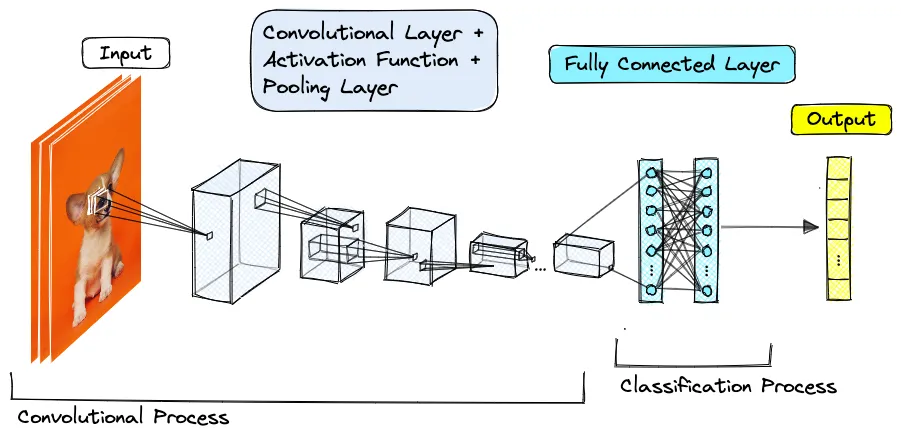
1.2.2 图像向量化(Image Embedding)
将图像数据转换为向量的过程。卷积神经网络和自编码器都是用于图像向量化的有效工具,前者通过训练提取图像特征并转换为向量,后者则学习图像的压缩编码以生成低维向量表示。
卷积神经网络(CNN)
- 通过训练卷积神经网络模型,我们可以从原始图像数据中提取特征,并将其表示为向量。例如,使用预训练的模型(如VGG16, ResNet)的特定层作为特征提取器。
自编码器(Autoencoders)
这是一种无监督的神经网络,用于学习输入数据的有效编码。在图像向量化中,自编码器可以学习从图像到低维向量的映射。

1.2.3 视频向量化(Vedio Embedding)
视觉块的引入
为了将视觉数据转换成适合生成模型处理的格式,研究者提出了视觉块嵌入编码(visual patches)的概念。这些视觉块是图像或视频的小部分,类似于文本中的词元。
处理高维数据
在处理高维视觉数据时(如视频),首先将其压缩到一个低维潜在空间。这样做可以减少数据的复杂性,同时保留足够的信息供模型学习。

使用patches,可以对视频、音频、文字进行统一的向量化表示**,和大模型中的 tokens 类似**
1.3 向量距离计算方式
==Euclidean Distance(欧几里得距离)(L2)==
几何距离
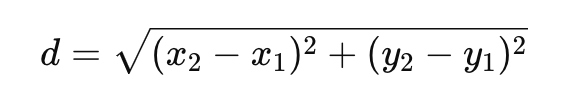
- 欧几里得距离是最常见、最直观的“几何距离”衡量方法。
- 广泛应用于聚类 (Clustering)、kNN (k-Nearest Neighbors) 等场景,尤其在数值型、连续型数据上使用频率非常高。
- 在低维度空间里直观且易于理解,但在高维度空间里往往会遇到“维度灾难”问题,欧几里得距离的分辨力可能会下降。
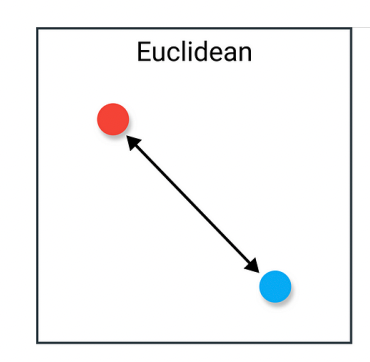
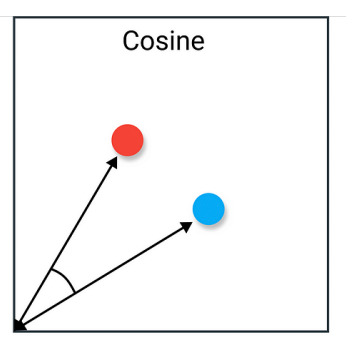
==Cosine Distance(余弦距离/相似度)==
余弦相似度(Cosine Similarity)测量的是两个向量夹角的相似度,可用下面的公式表示:
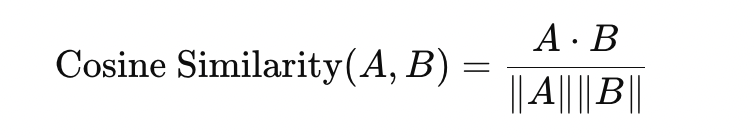
- 适合用来比较方向而非绝对大小的相似度,在文本向量化、推荐系统、自然语言处理等场景被大量使用。
- 当我们关心的是不同向量之间的“相似角度”而不太关注向量的具体长度时,余弦相似度/距离会更有效。
- 常用于高维稀疏向量(比如文本词频向量)场景。
==Hamming Distance(汉明距离)==
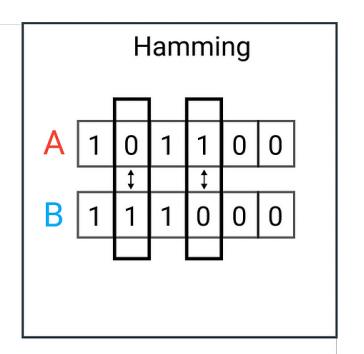
在两个等长的序列(通常是二进制串)之间,对应位置不同的个数就是它们的汉明距离。例如:A=101100,B=111000对应位置不同的共有 2 个,所以
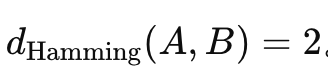
- 主要用于离散型数据(如二进制、字符串、编码数据)的差异度计算。
- 在纠错码 (Error-correcting codes)、信息传输和存储领域(比如 CRC、校验位)中至关重要。
- 用于比较两个 DNA 序列时出现多少个碱基不一样,也可用汉明距离来衡量。
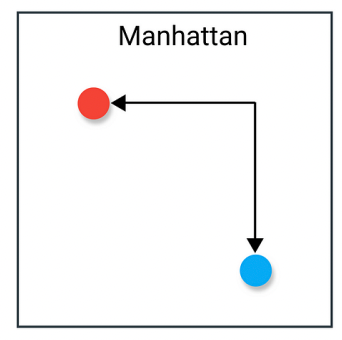
==Manhattan Distance(曼哈顿距离)(L1)==
又称 L1 距离,指在各维度上取绝对差值再相加,例如二维空间中:
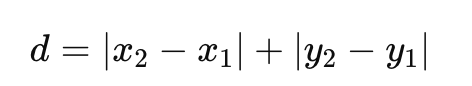
这好像在“城市街道”中行走,每次只能走水平或垂直方向。
- 当特征是绝对值差的累积更有意义时,可选曼哈顿距离。
- 在一些稀疏模型中(如 L1 正则)会与曼哈顿距离相关,并有利于特征选择。
- 在需要考虑“维度独立贡献”且对欧几里得距离不敏感时,也会选用它。
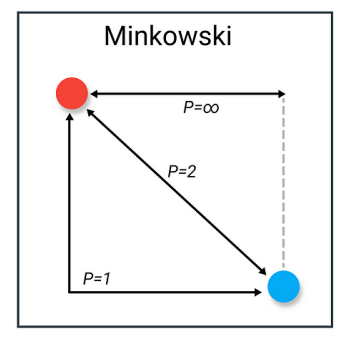
==Minkowski Distance(闵可夫斯基距离)==
是欧几里得距离(p=2)、曼哈顿距离(p=1)等的广义形式,p→∞ 时,就演化为 Chebyshev Distance,公式为:
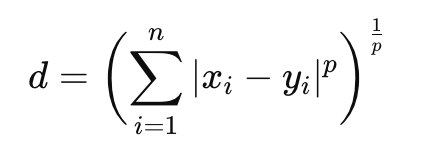
- 提供了一个可调节的尺度,可以根据不同数据分布或需求,选择合适的 p。
- 在实践中常用 p=1(曼哈顿距离)、p=2(欧几里得距离),有时也会用到介于 1 和 2 之间的非整数 p。
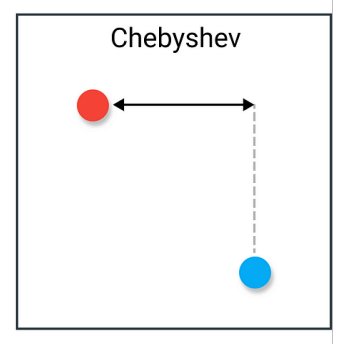
==Chebyshev Distance(切比雪夫距离)(L∞ )==
又称 L∞ 距离,定义为各维度坐标差值绝对值的最大值:
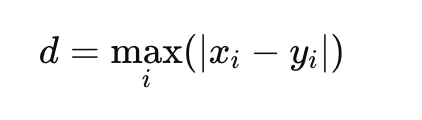
- 适合用在“棋盘距离”概念下:国际象棋中国王走一步最多可以改变行和列各 1,如果两个点在同一个“king move”距离里则 Chebyshev 距离较小。
- 某些最坏情况下的容忍度分析或者要求“任何一维差都不能超过某个限度”的场景,也可以使用 Chebyshev 距离。
==Jaccard Distance(杰卡德距离)==
Jaccard 相似系数(Jaccard Similarity) 常定义为
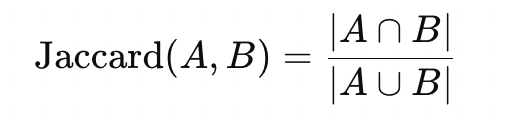
- 专门用来衡量集合之间的相似度或距离,常见于集合、布尔向量或稀疏数据表示场景(例如文档词集合)。
- 在信息检索、推荐系统和社交网络分析(用用户的兴趣标签作为集合)中很常用。
- 当想关注“集合之间真正重叠部分”在整体里的比例时,Jaccard 会更加合适。
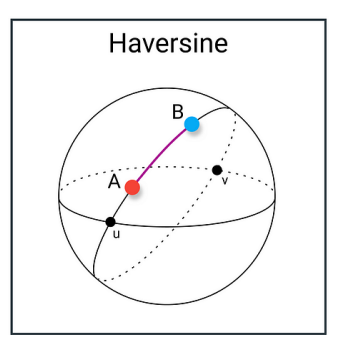
==Haversine Distance(哈夫萨因距离)==
主要用于地球表面上两点之间的球面距离计算。给定两点的经纬度 (lat1,lon1) 和 (lat2,lon2),它基于球面大圆距离公式(Great-circle distance),更加适合实际地理位置的距离估算。
- 适合用在地理坐标(如 GPS 坐标)计算距离的场合,比简单的欧几里得公式更准确地考虑地球的球面特性。
- 地图应用(测算两个地理位置之间的最短飞行距离)、定位服务等都会用到。
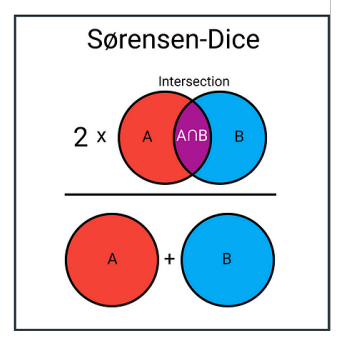
==Sørensen-Dice Coefficient(索伦森-骰子系数)/ Distance==
定义Sørensen-Dice 相似系数通常定义为
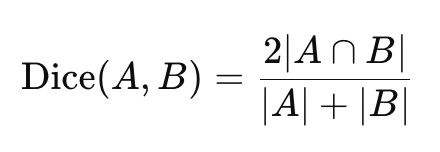
可以引申出相应的距离度量为
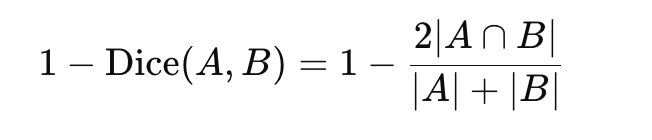
- 与 Jaccard 相似度都属于度量集合或二进制向量相似度的常用指标,但 Dice 会更关注“交集在两个集合规模总和里的占比”。
- 在信息检索、文本挖掘等需要对集合或特征子集比较的场景下常用。
- 对于小规模的集合,Dice 可能更加稳定;而对于大规模稀疏集合,Jaccard 与 Dice 在使用上常可以互换。
二、向量数据库(以 Milvus 为例)
2.1 为什么要使用向量数据库?
向量正逐步崭露头角,有望成为AI时代的数据交换标准,而向量数据库,现在有望成为 AI 时代的数据底座
2.2 Milvus 介绍
2.2.1 整体架构
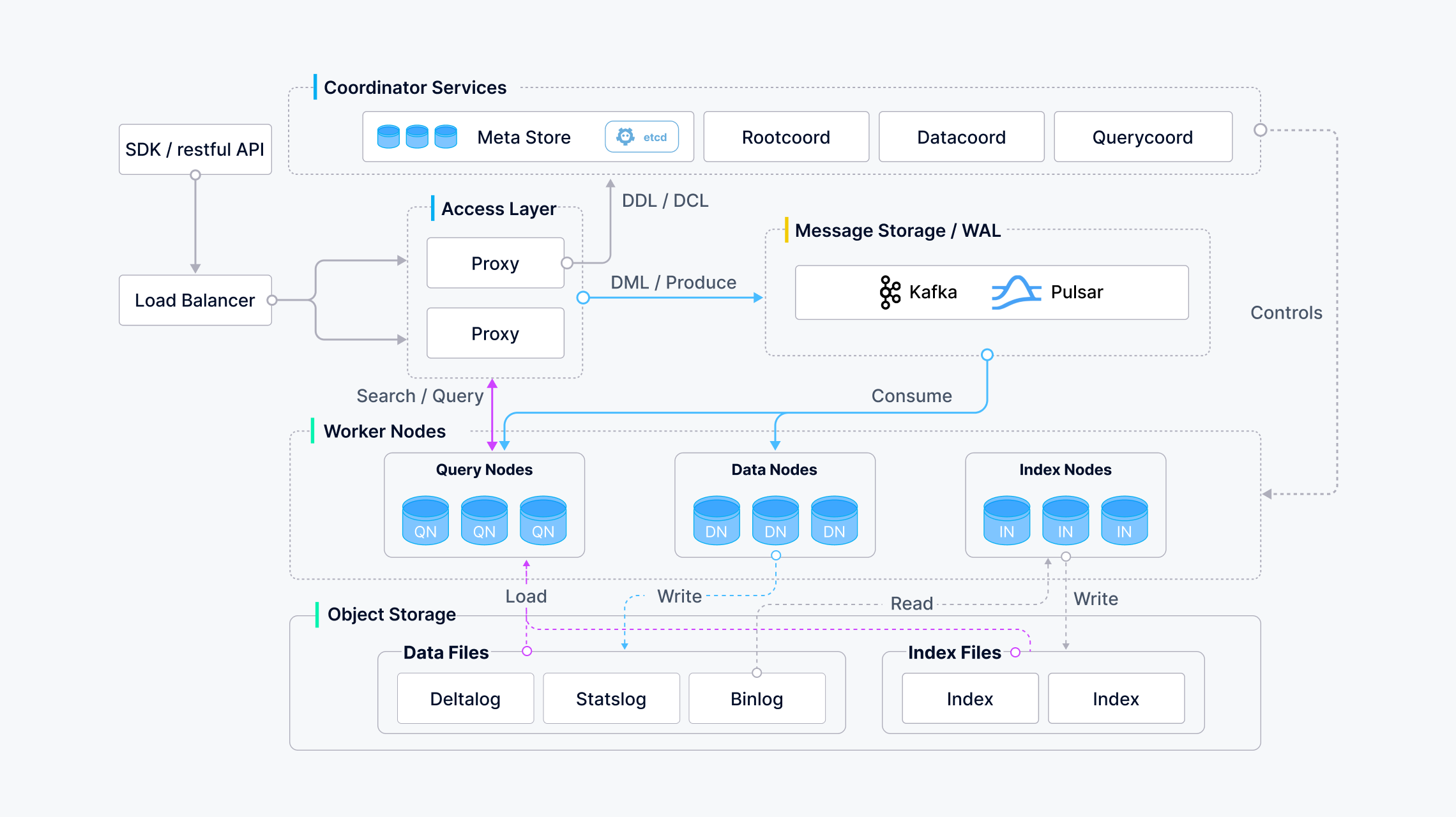
接入层
- LoadBalancer
- 使用 Nginx、Kubernetes Ingress、NodePort 和 LVS 等负载均衡组件提供统一的服务地址
- Proxy
- 代理会对中间结果进行聚合和后处理,然后再将最终结果返回给客户端
协调服务
- Rootcoord
- 根协调器处理数据定义语言(DDL)和数据控制语言(DCL)请求,如创建或删除 Collections、分区或索引,以及管理 TSO(时间戳 Oracle)和时间刻度签发。
- Querycoord
- 数据协调器管理数据节点和索引节点的拓扑结构,维护元数据,并触发刷新、压缩和索引构建以及其他后台数据操作。
- Datacoord
- 数据协调器管理数据节点和索引节点的拓扑结构,维护元数据,并触发刷新、压缩和索引构建以及其他后台数据操作。
工作节点
- QueryNode
- 查询节点通过订阅日志代理检索增量日志数据并将其转化为不断增长的片段,从对象存储中加载历史数据,并在向量和标量数据之间运行混合搜索。
- DataNode
- 数据节点通过订阅日志代理检索增量日志数据,处理突变请求,将日志数据打包成日志快照并存储在对象存储中。
- IndexNode
- 索引节点构建索引。 索引节点不需要常驻内存,可以使用无服务器框架来实现。
存储
- meta store
- 元存储存储元数据的快照,如 Collections Schema 和消息消耗检查点。元数据的存储要求极高的可用性、强一致性和事务支持,因此 Milvus 选择 etcd 作为元存储。Milvus 还使用 etcd 进行服务注册和健康检查。
- object storage
- 对象存储用于存储日志快照文件、标量和向量数据的索引文件以及中间查询结果。Milvus 使用 MinIO 作为对象存储。
- message storage
- 日志代理是一个支持回放的发布子系统。它负责流数据持久化和事件通知。当工作节点从系统故障中恢复时,它还能确保增量数据的完整性。Milvus 集群使用 Pulsar 作为日志代理;Milvus 单机使用 RocksDB 作为日志代理。此外,日志代理可以随时替换为 Kafka 等流式数据存储平台。
2.2.2 检索引擎 Knowwhere
如果把 Milvus 比喻为一辆跑车,Knowhere 就是这辆跑车的引擎。Knowhere 的定义范畴分为狭义和广义两种。狭义上的 Knowhere 是下层向量查询库(如Faiss、HNSW、Annoy)和上层服务调度之间的操作接口。同时,异构计算也由 Knowhere 这一层来控制,用于管理索引的构建和查询操作在何种硬件上执行, 如 CPU 或 GPU,未来还可以支持 DPU/TPU/……这也是 Knowhere 这一命名的源起 —— know where。广义上的 Knowhere 还包括 Faiss 及其它所有第三方索引库。因此,可以将 Knowhere 理解为 Milvus 的核心运算引擎。
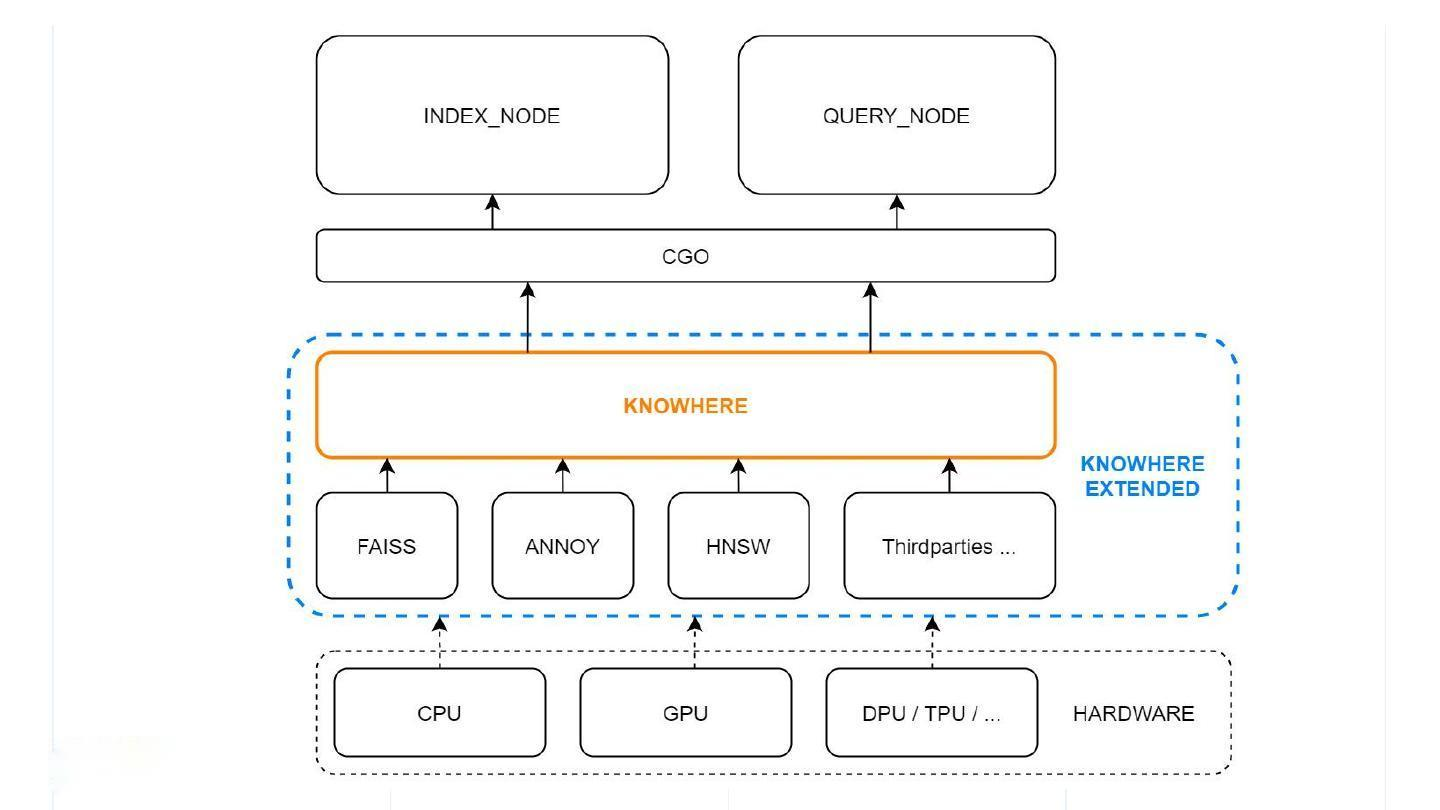
2.2.3 Milvus的数据模型
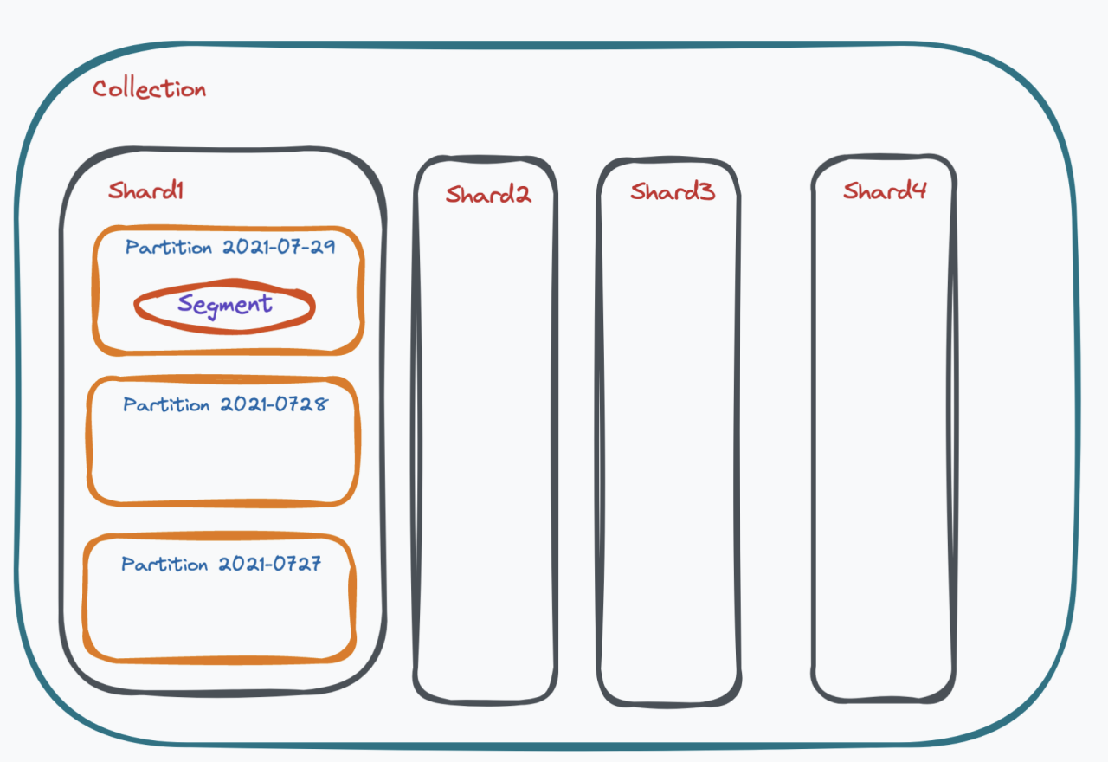
- Database,一个 milvus 集群可以设置多个 database,下属多个 collection
- Collection,因为是分布式系统,所以一个 collection 可以被加载到多个 node 上,每个 node 加载该 collection 的一个分片,每个分片称为 shard
- Partition,数据的逻辑分片,可加速查询
- Segment,是 Partition 中的数据块
在 Milvus 中查询的最小单位是 segment,对 collection 的查询操作最终会被分解为对该 collection 或若干 partition 中所有 segment 的查询。最后,对所有 segment 的查询结果进行归并,并得到最终结果。
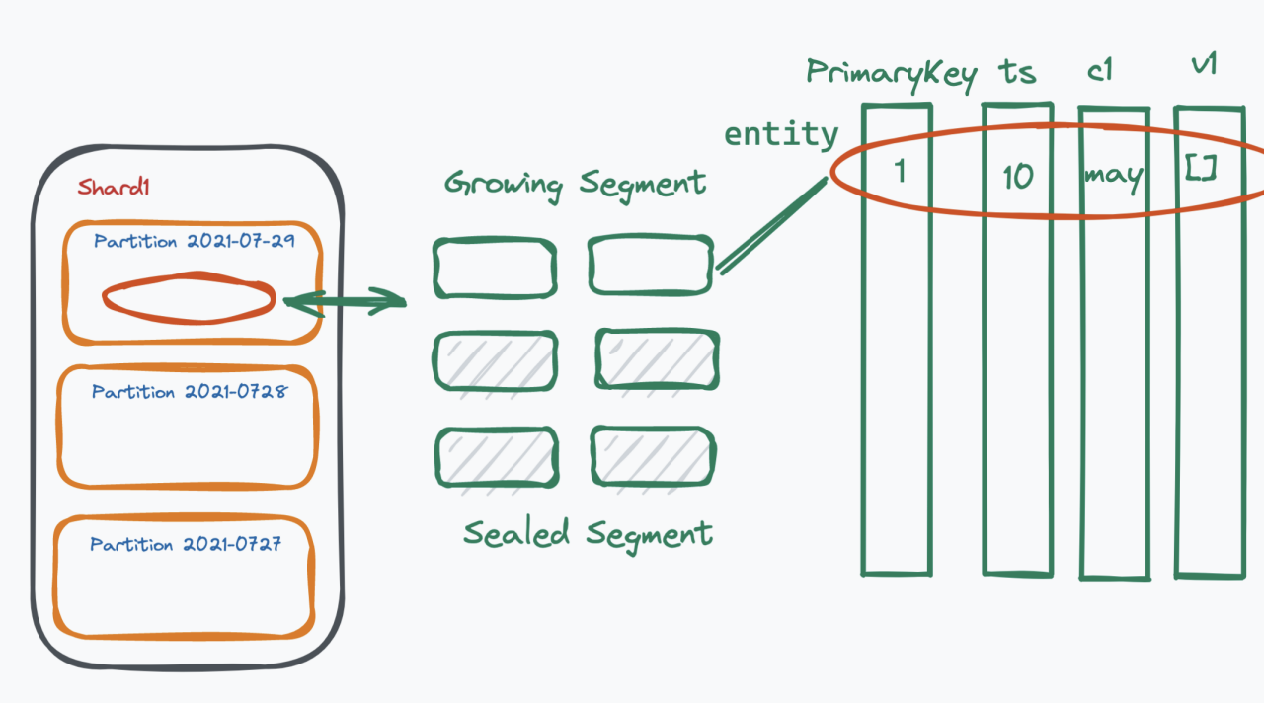
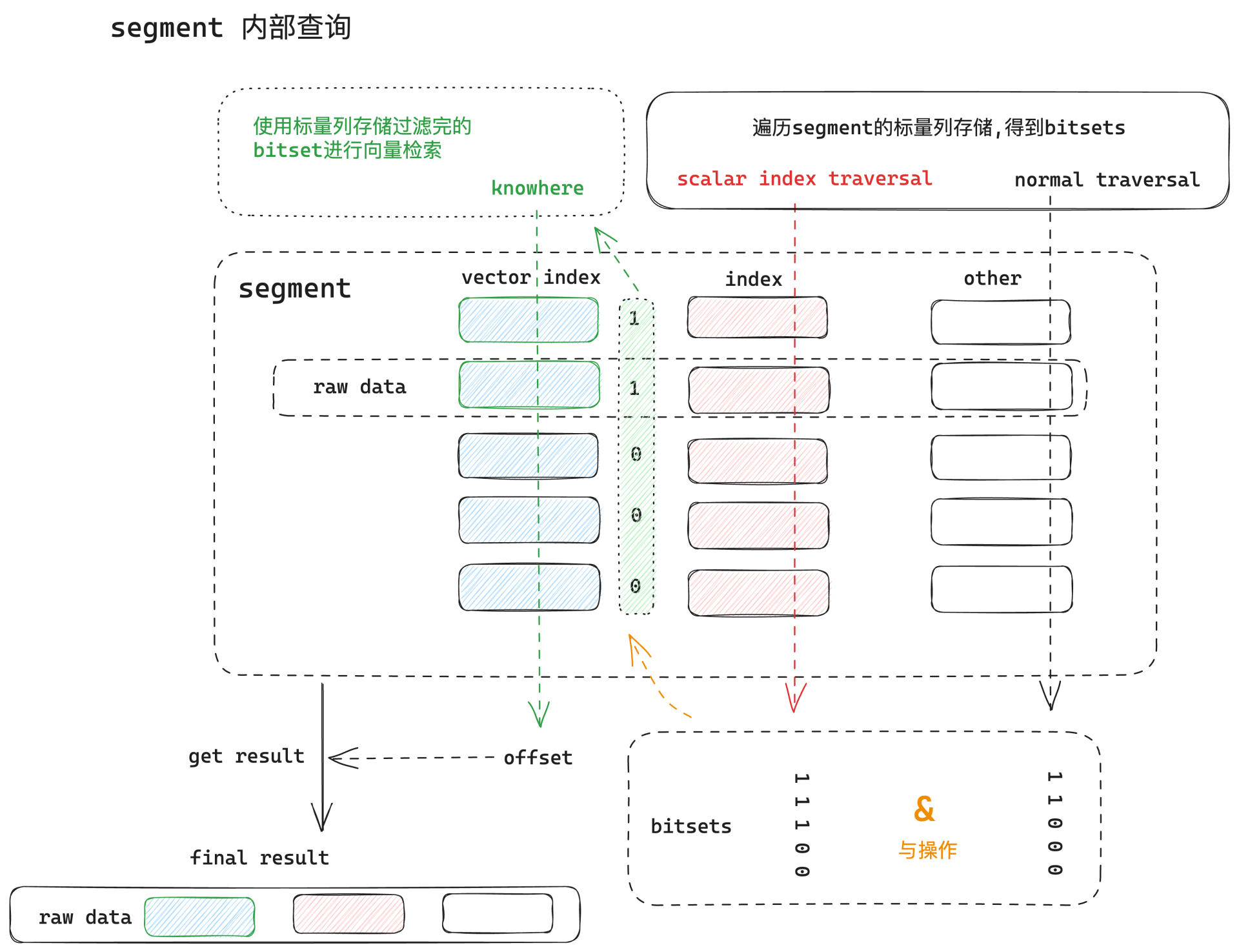
2.2.4 检索引擎的底层执行逻辑
2.3 向量索引
索引性能benchmark:https://ann-benchmarks.com/index.html
2.3.1 检索方式 KNN VS ANN——检索方式的选择
==KNN (K-Nearest Neighbor)==
在向量检索中表示精确最近邻搜索,目标是找到查询向量在高维空间中真正距离最近的 K 个向量
工作原理
KNN 的核心思想是通过计算查询向量与数据库中每个向量的距离,找到最近的 K 个向量。关键步骤如下:
- 距离度量: 使用欧几里得距离、余弦相似度、内积等度量方式。
- 线性扫描: 遍历所有向量,计算查询点到每个向量的距离,按距离排序,返回前 K 个。
- 数据结构优化:
- KD-Tree: 将数据划分为超平面以加速低维检索。
- Ball Tree: 按距离分割向量点云形成层次结构,适合中低维检索。
优点
- 精确性高: 能保证结果是最精确的 K 个邻居。
- 简单直观: 实现上无需复杂的预处理或索引构建。
缺点
- 计算开销大:
- 如果数据集有 n个向量,每个向量有 d 个维度,则线性扫描需要 O(n×d)的计算。
- 在数据量大或维度高的情况下,性能显著下降(“维度灾难”)。
- 不适合大规模数据: 当数据量或查询次数增加时,响应时间可能过长。
使用场景
- 需要精确结果的应用,如:
- 医疗图像匹配。
- 法律文档检索。
- 高精度推荐系统(小数据集)。
==ANN (Approximate Nearest Neighbor)==
ANN 是一种近似搜索技术,用于快速查找与查询向量相似的邻居,但不保证结果完全精确,允许一定误差。
工作原理
ANN 的核心思想是通过减少计算和搜索范围,以加速检索。关键步骤如下:
- 向量降维:
- 将高维向量映射到低维空间,降低计算复杂度。
- 常见方法:PCA(主成分分析)、随机投影。
- 索引构建:
- 使用特定的数据结构(如哈希表或图)将向量组织成高效的索引。
- 近似查找:
- 使用索引快速缩小检索范围,只计算小部分向量的距离。
常见实现方法
- 基于哈希的技术:LSH (Locality-Sensitive Hashing)
- 核心原理:
- 构建哈希函数组,将相似的向量映射到同一桶中。
- 查询时只需在相关桶中搜索,减少搜索范围。
- 适用场景: 适用于低维数据和欧几里得距离度量。
- 核心原理:
- 基于图的技术:HNSW (Hierarchical Navigable Small World)
- 核心原理:
- 构建分层图,节点表示向量,边表示向量之间的相似性。
- 搜索时从上层开始逐层向下,最终找到近似邻居。
- 优势:
- 高效处理高维数据。
- 在工业界应用广泛(如 Milvus、FAISS)。
- 核心原理:
- 基于量化的技术:PQ (Product Quantization)
- 核心原理:
- 将向量划分为子空间,并为每个子空间创建码本,压缩存储。
- 查询时通过码本进行快速距离计算。
- 优势:
- 存储效率高,适合超大规模数据。
- 核心原理:
- 基于树的技术:Annoy
- 核心原理:
- 构建多个随机分割树,通过投影缩小检索范围。
- 查询时遍历多棵树以找到近似邻居。
- 优势:
- 实现简单,适合分布式场景。
优点
- 实现简单,适合分布式场景。
- 核心原理:
- 速度快: 可显著提升高维和大规模数据的查询速度。
- 扩展性好: 适合处理亿级规模的向量检索。
- 存储优化: 一些方法(如 PQ)还能大幅压缩向量存储。
缺点
- 近似结果: 可能无法找到真正最近的邻居。
- 误差可控性: 需要平衡查询速度与结果精度。
使用场景
- 高速检索需求的应用,如:
- 搜索引擎(Google、Bing)。
- 大规模推荐系统(音乐、视频)。
- 自然语言处理(语义向量检索)。
目前在 AI 领域,主流使用 ANN 索引
2.3.2 量化方式 PQ、SQ——压缩索引大小,降低内存占用
==PQ(Product Quantization)—— 产品量化(乘积量化)==
核心概念
- 产品量化是一种分块量化方法,将高维向量分为多个低维子空间,对每个子空间单独进行量化。
- 核心思想是通过子空间量化实现高效压缩,同时保留全局信息的近似性。
实现步骤
- 向量分块:
- 将高维向量分成 m 个低维子向量。例如,128 维向量可以分为 4 个 32 维子向量。
- 码本训练:
- 对每个子空间单独训练一个码本(通常通过 K-Means 聚类),每个码本中包含 k 个质心(即量化中心点)。
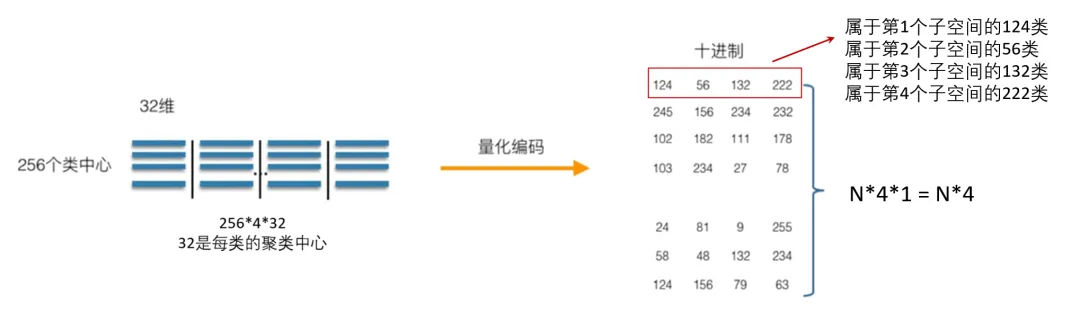
- 量化编码:
- 将每个子向量映射为其所在子空间码本中的最近质心索引。
- 存储的索引比直接存储原始向量占用更少空间。
- 检索时的重构:
- 检索时,将查询向量也分块,依次查询每个子空间的质心,计算近似距离。
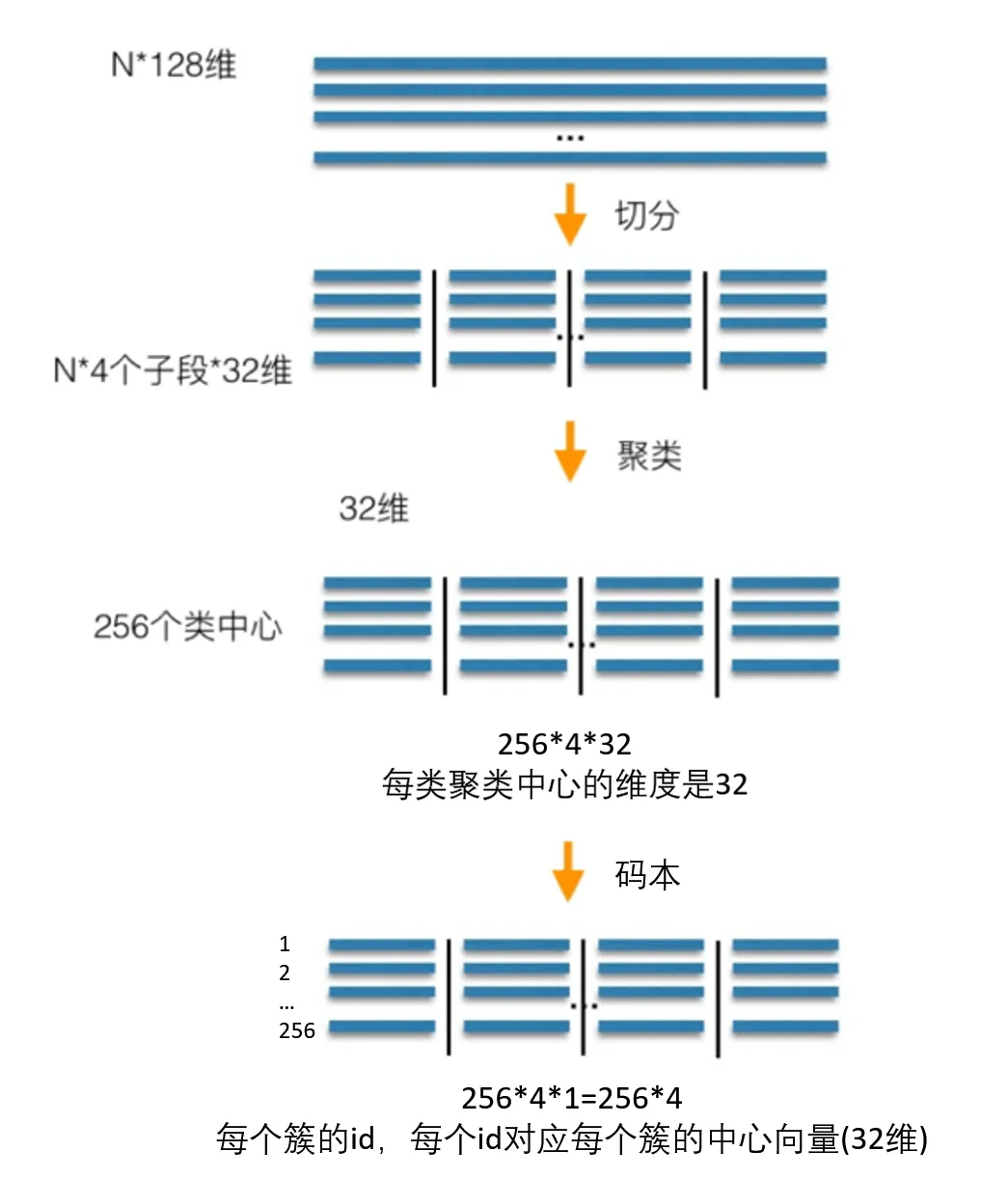
- 检索时,将查询向量也分块,依次查询每个子空间的质心,计算近似距离。
==SQ(Scalar Quantization)—— 标量量化==
核心概念
- 标量量化是对每个向量维度单独进行量化,将其值映射到固定范围内的一组离散值(标量)。
- 核心思想是通过简单的数值离散化压缩向量存储。
实现步骤
- 范围确定:
- 对每个维度的值确定最大值和最小值范围。
- 离散化:
- 将每个维度的值离散到有限数量的标量(如 8 位整数),通常通过线性映射实现:
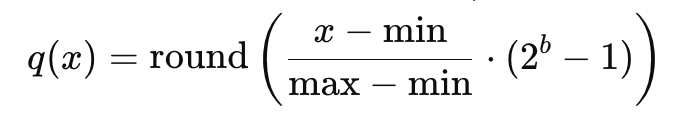
- 将每个维度的值离散到有限数量的标量(如 8 位整数),通常通过线性映射实现:
b 是量化位数。
- 存储:
- 存储离散值的索引代替原始值。
2.3.3 聚类算法——K-Means
聚类(Clustering) 简而言之,就是使用某种静态分类方法将一组数据自动地分成多个子集。由于研究对象和使用场景不同,聚类算法的种类也十分多样。常见的模型包括 Connectivity 和 Centroid 等,而 K-Means 则是 Centroid 模型的典型代表之一。
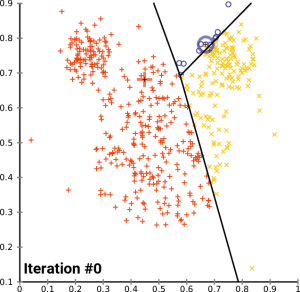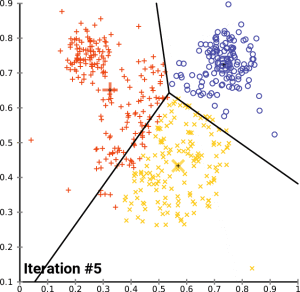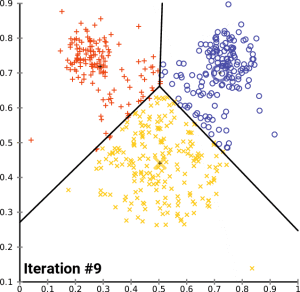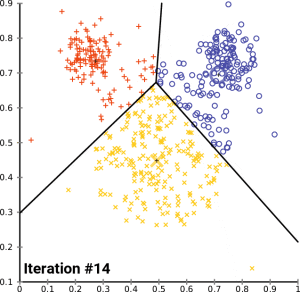
以下是 K-Means 聚类的流程:
- **随机选定重心(Centroid):**在数据集中随机选取 k 个点,并将它们视为初始的重心。
- **划分子集:**根据这 k 个重心把数据分成 k 个子集,每个子集都对应一个重心。
- **分配数据点:**对数据集中的每个向量与各重心进行距离计算,并将其分配给距离最近的重心所对应的子集。
- **更新重心并迭代:**重新计算各子集的重心,使其在该子集内更加均匀。随后重复步骤 2 和 3,通常进行多次迭代(i 次)直到收敛或达到预定的迭代次数。
2.3.4 倒排文件索引 IVF
概念:
- 将高维向量数据划分为多个组(或称“桶”)。
- 每个组对应一个“倒排表”(Inverted List),存储属于该组的向量。
- 查询时,首先确定查询向量属于哪个组,只在该组的倒排表中进行进一步搜索,从而减少计算量
实现步骤
- 聚类分桶:
- 通过聚类算法(如 K-Means)将数据库向量分成 K 个簇。
- 每个簇的中心点称为簇心或质心,所有簇心组成一个“簇心集合”。
- 每个簇对应一个倒排表,存储落在该簇中的所有向量的索引。
- 构建倒排文件:
- 数据库中的每个向量都根据与簇心的距离,分配到最近的簇。
- 簇内的向量索引存储在对应的倒排表中。
- 查询阶段:
- 对查询向量进行近似检索:
- 首先计算查询向量到所有簇心的距离,找到最近的 n 个簇(称为“候选簇”)。
- 在这些候选簇的倒排表中,进行精确或近似的最近邻搜索。
- 对查询向量进行近似检索:
2.3.5 索引枚举
==FLAT——暴力检索的实现==
FLAT 的精确度很高,因为它采用的是穷举搜索方法,这意味着每次查询都要将目标输入与数据集中的每一组向量进行比较。这使得 FLAT 成为我们列表中速度最慢的索引,而且不适合查询海量向量数据。在 Milvus 中,FLAT 索引不需要任何参数,使用它也不需要数据训练。
==IVF_FLAT——倒排暴力检索==
IVF_FLAT 将向量数据划分为nlist 个聚类单元,然后比较目标输入向量与每个聚类中心之间的距离。根据系统设置查询的簇数 (nprobe),相似性搜索结果将仅根据目标输入与最相似簇中向量的比较结果返回--大大缩短了查询时间。
通过调整nprobe ,可以在特定情况下找到准确性和速度之间的理想平衡。IVF_FLAT 性能测试结果表明,随着目标输入向量数 (nq) 和要搜索的簇数 (nprobe) 的增加,查询时间也会急剧增加。
IVF_FLAT 是最基本的 IVF 索引,每个单元中存储的编码数据与原始数据一致。
==IVF_SQ8——倒排 SQ 量化索引,减少 70-75% 的磁盘、CPU 和 GPU 内存消耗==
IVF_FLAT 不进行任何压缩,因此它生成的索引文件大小与原始的非索引向量数据大致相同。例如,如果原始的 1B SIFT 数据集为 476 GB,那么其 IVF_FLAT 索引文件就会稍小一些(~470 GB)。将所有索引文件加载到内存中将消耗 470 GB 的存储空间。
当磁盘、CPU 或 GPU 内存资源有限时,IVF_SQ8 是比 IVF_FLAT 更好的选择。这种索引类型可以通过执行标量量化(SQ)将每个 FLOAT(4 字节)转换为 UINT8(1 字节)。这样可以减少 70-75% 的磁盘、CPU 和 GPU 内存消耗。对于 1B SIFT 数据集,IVF_SQ8 索引文件仅需 140 GB 的存储空间。
==IVF_PQ——倒排 PQ 量化,索引文件比 IVF_SQ8 更小==
PQ (乘积量化)将原始高维向量空间均匀分解为 低维向量空间的笛卡尔乘积,然后对分解后的低维向量空间进行量化。乘积量化不需要计算目标向量与所有单元中心的距离,而是能够计算目标向量与每个低维空间聚类中心的距离,大大降低了算法的时间复杂度和空间复杂度。
IVF_PQ 先进行 IVF 索引聚类,然后再对向量的乘积进行量化。其索引文件比 IVF_SQ8 更小,但在搜索向量时也会造成精度损失。
| 参数 | 说明 |
|---|---|
nlist | 集群单位数 |
m | 乘积量化因子数 |
nbits | [可选项] 每个低维向量的存储位数。 |
nprobe | 要查询的单位数 |
==SCANN —— Google 推出的非常先进的索引==
https://github.com/google-research/google-research/tree/master/scann
ScaNN(可扩展近邻)在向量聚类和乘积量化方面与 IVF_PQ 相似。它们的不同之处在于乘积量化的实现细节和使用 SIMD(单指令/多数据)进行高效计算。
==HNSW——主流的图索引==
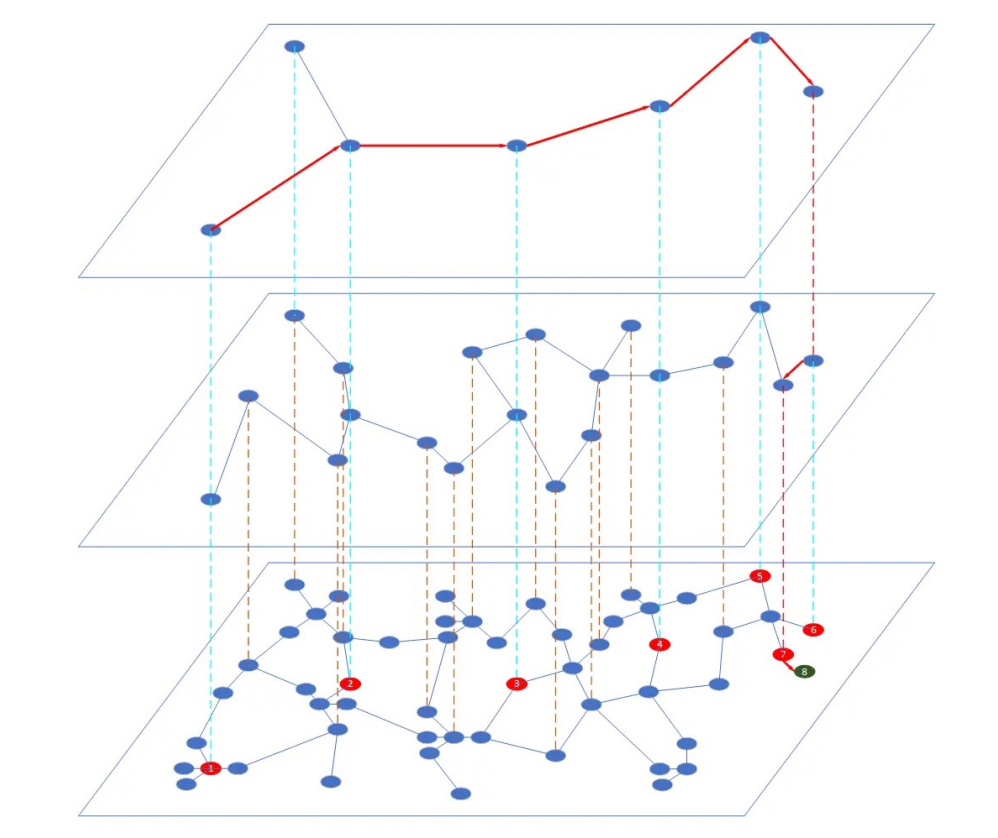
HNSW(分层导航小世界图)是一种基于图的索引算法。它根据一定的规则为图像建立多层导航结构。在这个结构中,上层较为稀疏,节点之间的距离较远;下层较为密集,节点之间的距离较近。搜索从最上层开始,在这一层找到离目标最近的节点,然后进入下一层开始新的搜索。经过多次迭代后,就能快速接近目标位置。
HNSW索引在构建过程中,必须由⽤户指定的建索引参数,除了距离算法之外,只有2个参数:
- M:给每个新插⼊的点建议的边的数量,M的合理值在2和200之间,⼀般来说,M越⼤,检索的召回率也会更好,但是图结构占⽤的额外索引空间也会越⼤,M=16或32都是⽐较常⻅的选择
- efConstruction:建索引过程中,每个点的候选最近邻数量,该参数越⼤,索引的质量越好,建索引的计算量也越⼤,该参数对建索引的耗时有⾮常⼤的影响,取值⼀般为M的数倍⾄⼀个数量级,100或200都是常⻅的取值选择
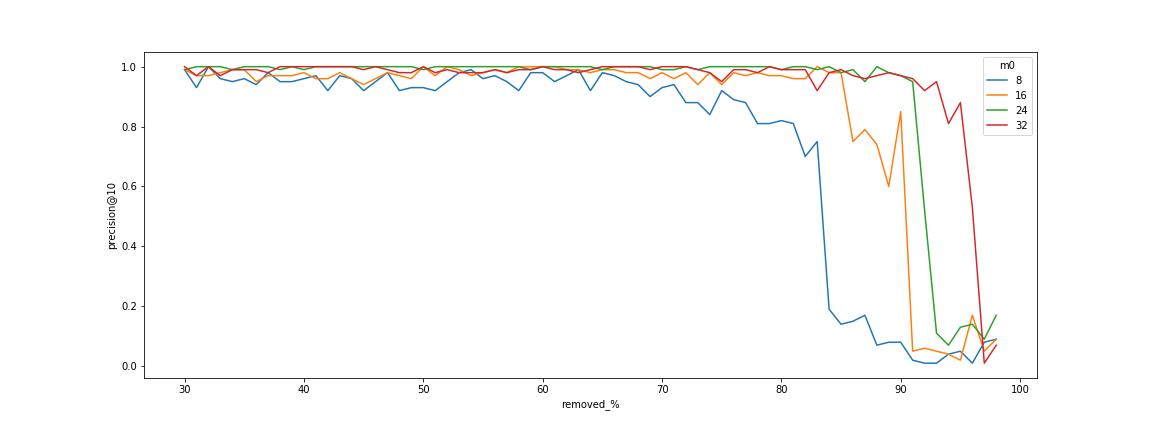
HNSW索引性能退化
在带过滤的检索场景中,如果被过滤掉的数据⽐例超过⼀定的阈值之后,HNSW索引的召回率会急剧下降,甚⾄是检
索延迟的急剧上升,使得算法失效。此问题在算法层⾯⾄今尚未得到很好的解决,已有的解决⽅法包括:
- 设定更⼤的M值,从图可以看出,M越⼤,退化点越靠右,但更⼤的M也会带来更⼤的内存开销
- 设定过滤⽐例阈值底线,⽐如5%、7%等,当满⾜过滤条件的数据不⾜这个⽐例时,直接退化为KNN检索

==HNSW_PQ——HNSW PQ 量化索引==
HNSW PQ 量化索引,详情参考HNSW
==HNSW_SQ——HNSW SQ 量化索引==
HNSW SQ 量化索引,详情参考HNSW
2.3.6 索引使用场景比较
| 索引 | 场景 |
|---|---|
| FLAT | - 数据集相对较小 - 需要 100% 的召回率 |
| IVF_FLAT | - 高速查询 - 要求尽可能高的召回率 |
| IVF_SQ8 | - 极高速查询 - 内存资源有限 - 可接受召回率略有下降 |
| IVF_PQ | - 高速查询 - 内存资源有限 - 可略微降低召回率 |
| HNSW | - 极高速查询 - 要求尽可能高的召回率 - 内存资源大 |
| HNSW_SQ | - 非常高速的查询 - 内存资源有限 - 可略微降低召回率 |
| HNSW_PQ | - 中速查询 - 内存资源非常有限 - 在召回率方面略有妥协 |
| SCANN | - 极高速查询 - 要求尽可能高的召回率 - 内存资源大 |
2.4 向量数据库的使用优化
成本优化
在向量数据库实际使用过程中,主要的成本在于 内存、CPU、磁盘,从占比上来说,内存成本远远高于 CPU 和磁盘,所以,一般我们通过优化内存占用,来进行成本优化,一般通过调优索引来实现
稳定性优化
Milvus 大部分节点是无状态服务,有状态服务需要进行稳定性优化的,一般是 ETCD、MinIO,关于 ETCD 和 MinIO 优化不展开


