
github 仓库:
GitHub - Project-HAMi/HAMi: Heterogeneous AI Computing Virtualization Middleware
GitHub - Project-HAMi/HAMi-core: HAMi-core compiles libvgpu.so, which ensures hard limit on GPU in container
官网:Open, Device Virtualization, VGPU, Heterogeneous AI Computing | HAMi
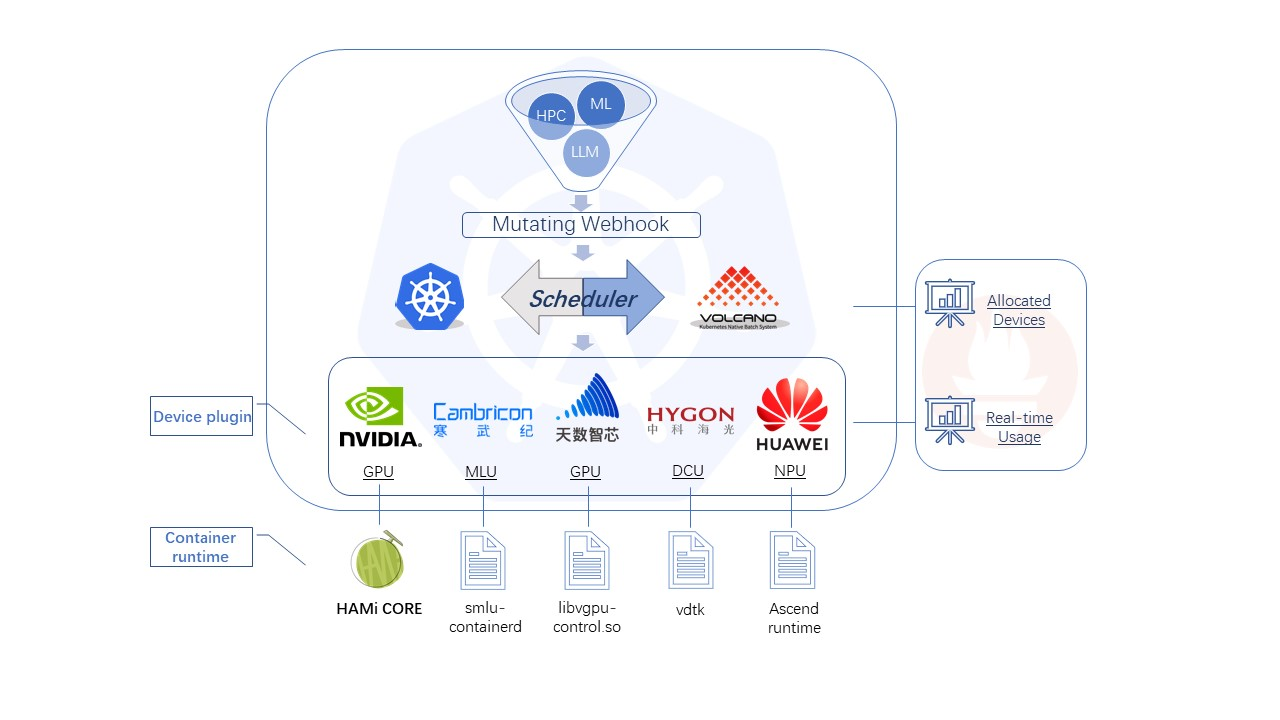

一、介绍
HAMi (Heterogeneous AI Computing Virtualization Middleware) 以前称为 k8s-vGPU-scheduler,是一个 'all-in-one' Chart,用于管理 k8s 集群中的异构 AI 计算设备。它能够提供共享异构 AI 设备的能力,并在任务之间提供资源隔离。
对于 nVidia GPU 的虚拟化核心技术才 hami-core 仓库中
二、hami 虚拟化核心原理
2.1 函数劫持机制
HAMi-core通过动态链接库劫持(Library Interposition)技术拦截CUDA函数调用。核心实现在src/libvgpu.c:
FUNC_ATTR_VISIBLE void* dlsym(void* handle, const char* symbol) {
LOG_DEBUG("into dlsym %s",symbol);
pthread_once(&dlsym_init_flag,init_dlsym);
if (real_dlsym == NULL) {
real_dlsym = dlvsym(RTLD_NEXT,"dlsym","GLIBC_2.2.5");
vgpulib = dlopen("/usr/local/vgpu/libvgpu.so",RTLD_LAZY);
if (real_dlsym == NULL) {
LOG_ERROR("real dlsym not found");
real_dlsym = _dl_sym(RTLD_NEXT, "dlsym", dlsym);
if (real_dlsym == NULL)
LOG_ERROR("real dlsym not found");
}
}
// 拦截以cu开头的CUDA函数
if (symbol[0] == 'c' && symbol[1] == 'u') {
// 预初始化
if (strcmp(symbol,"cuGetExportTable")!=0)
pthread_once(&pre_cuinit_flag,(void(*)(void))preInit);
void *f = real_dlsym(vgpulib,symbol);
if (f!=NULL)
return f;
}
// ...
return real_dlsym(handle, symbol);
}
==HAMi-core重写了系统的dlsym函数(动态链接符号查找函数),当应用程序尝试加载CUDA函数时,会返回HAMi-core中的替代实现,而非原始CUDA库中的实现。==
2.1.1 LD_PRELOAD机制详解
LD_PRELOAD是Linux/Unix系统中的一个动态链接器环境变量,它允许用户在程序运行前预先加载指定的共享库,从而可以覆盖原本的库函数实现。这是一种强大的"库函数劫持"技术。
工作原理
- 动态链接器优先级:在Linux系统加载动态链接库时遵循以下顺序:
- LD_PRELOAD环境变量指定的库
- 程序编译时指定的库
- 标准系统库路径(/lib, /usr/lib等)
- 符号解析顺序:当程序调用一个函数时,动态链接器会按照上述顺序查找函数符号。如果LD_PRELOAD指定的库中存在同名函数,则会使用这个版本,而不是标准库中的版本。
- 运行时劫持:这种机制允许在不修改原程序源代码或重新编译的情况下,"拦截"和替换程序的函数调用。
HAMi-core中的应用
# HAMi-core使用示例
export LD_PRELOAD=./libvgpu.so
export CUDA_DEVICE_MEMORY_LIMIT=1g
当设置上述环境变量后,任何CUDA程序在加载时:
- 首先加载libvgpu.so
- libvgpu.so中包含与CUDA API同名的函数(如cuMemAlloc_v2, cuLaunchKernel等)
- 当程序调用CUDA函数时,实际执行的是libvgpu.so中的对应函数
- libvgpu.so中的函数可以在执行原始CUDA函数前后增加额外逻辑(如内存限制检查)
从HAMi-core的代码可以看到,它重写了系统的dlsym函数
2.2 显存虚拟化
显存虚拟化的核心实现在src/multiprocess/multiprocess_memory_limit.c和src/cuda/memory.c
- 从环境变量中读取显存限制值
void do_init_device_memory_limits(uint64_t* arr, int len) {
// 从环境变量读取限制配置
size_t fallback_limit = get_limit_from_env(CUDA_DEVICE_MEMORY_LIMIT);
int i;
for (i = 0; i < len; ++i) {
char env_name[CUDA_DEVICE_MEMORY_LIMIT_KEY_LENGTH] = CUDA_DEVICE_MEMORY_LIMIT;
char index_name[8];
snprintf(index_name, 8, "_%d", i);
strcat(env_name, index_name);
size_t cur_limit = get_limit_from_env(env_name);
if (cur_limit > 0) {
arr[i] = cur_limit;
} else if (fallback_limit > 0) {
arr[i] = fallback_limit;
} else {
arr[i] = 0;
}
}
}
- 内存分配拦截:在src/cuda/memory.c中,HAMi-core实现了cuMemAlloc_v2等内存分配函数,并通过重写 dlsym 注入
DLSYM_HOOK_FUNC(cuMemAlloc_v2);:
CUresult cuMemAlloc_v2(CUdeviceptr* dptr, size_t bytesize) {
// 检查是否超出内存限制
if (check_oom()) {
// OOM处理
return CUDA_ERROR_OUT_OF_MEMORY;
}
// 调用实际的内存分配
CUresult res = CUDA_OVERRIDE_CALL(cuda_library_entry, cuMemAlloc_v2, dptr, bytesize);
// 更新内存使用记录
// ...
return res;
}
2.3 单进程利用率限制(SM利用率限制)
SM利用率限制通过时间片调度实现,核心代码在src/multiprocess/multiprocess_utilization_watcher.c:
- 通过环境变量获取SM限制
void do_init_device_sm_limits(uint64_t *arr, int len) {
size_t fallback_limit = get_limit_from_env(CUDA_DEVICE_SM_LIMIT);
if (fallback_limit == 0) fallback_limit = 100;
// ...设置每个设备的SM利用率限制
}
- 令牌桶限速(HAMi-core使用令牌桶算法控制GPU计算资源使用)
void rate_limiter(int grids, int blocks) {
// ...
if ((get_current_device_sm_limit(0)>=100) || (get_current_device_sm_limit(0)==0))
return; // 无限制
if (get_utilization_switch()==0)
return; // 关闭限制
// ...
do {
CHECK:
before_cuda_cores = g_cur_cuda_cores;
if (before_cuda_cores < 0) {
nanosleep(&g_cycle, NULL); // 等待令牌可用
goto CHECK;
}
after_cuda_cores = before_cuda_cores - kernel_size;
} while (!CAS(&g_cur_cuda_cores, before_cuda_cores, after_cuda_cores));
}
- 后台线程调整令牌发放数量
void* utilization_watcher() {
// ...
while (1){
nanosleep(&g_wait, NULL);
// ...
get_used_gpu_utilization(userutil, &sysprocnum);
// ...
if ((userutil[0]<=100) && (userutil[0]>=0)){
share = delta(upper_limit, userutil[0], share);
change_token(share); // 根据实际使用率调整令牌数量
}
// ...
}
}
- 单线程利用率限制
拦截Kernel启动,通过拦截cuLaunchKernel函数实现SM利用率限制
CUresult cuLaunchKernel(CUfunction f, unsigned int gridDimX, /* ... */) {
// ...
pre_launch_kernel();
if (pidfound==1){
rate_limiter(gridDimX * gridDimY * gridDimZ,
blockDimX * blockDimY * blockDimZ);
}
// 调用实际的kernel启动函数
CUresult res = CUDA_OVERRIDE_CALL(cuda_library_entry, cuLaunchKernel, /* ... */);
return res;
}
- ==令牌代表可用的GPU计算资源(CUDA核心/SM利用率)==
- ==Kernel启动前需要消耗对应数量的令牌==
- ==定期补充令牌,速率根据设定的SM利用率限制调整==
2.3.1 SM(流多处理器)基本概念
SM(Streaming Multiprocessor,流多处理器)是NVIDIA GPU架构的核心计算单元。
- 基本架构:
- 一个现代NVIDIA GPU包含多个SM(从几个到几十个不等)
- 每个SM包含:
- 多个CUDA核心(执行整数和浮点运算)
- 共享内存
- 寄存器
- 纹理单元
- 调度器
- 其他专用计算单元(如张量核心)
- 并行执行模型:
- SM以"线程束"(warp)为单位执行指令
- 一个线程束通常包含32个线程,同时执行相同的指令
- 多个线程束并发执行在一个SM上
以上是 GPU 虚拟化的核心概念



