
一、深度学习与数学基础
后续上传
二、Transformer介绍——LLM 的基础架构
attention is all you need:https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
https://arxiv.org/abs/1706.03762
https://lilianweng.github.io/posts/2023-01-27-the-transformer-family-v2/
大型 Transformer 模型如今已成为主流,为各种任务创造了最先进的成果,是目前最流行的神经网络架构。Transformer 模型的核心特点是其注意力机制。注意力机制允许模型在处理输入序列时,动态地关注序列中的不同部分,从而更好地捕捉上下文信息。
2.1 Transformer 架构总览
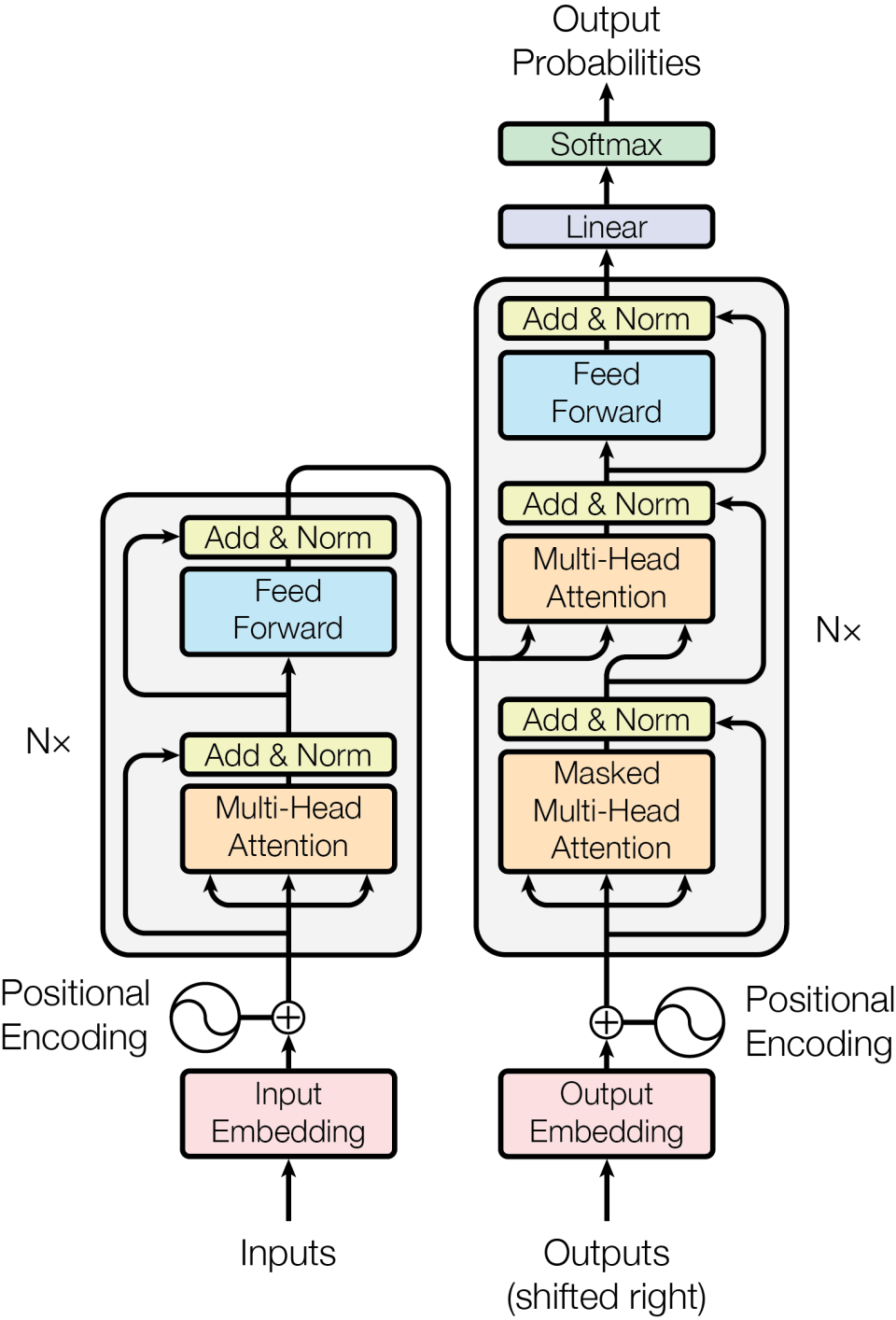

Encoder 由一组N=6个相同的层堆叠而成。每一层包含两个子层:第一个是 multi-head self-attention(多头自注意力机制),第二个是一个简单的、逐位置的全连接前馈网络。每个子层周围都使用了 residual connection(残差连接),并紧接着进行 layer normalization(层归一化)。也就是说,每个子层的输出为\text {LayerNorm}(x + \text {Sublayer}(x)),其中\text {Sublayer}(x)是该子层自身实现的函数。为了便于这些残差连接,模型中所有子层以及嵌入层的输出维度均为d_{model} = 512。
Decoder 也由堆叠的 N=6 个相同层组成。除了每个编码器层中的两个子层外,解码器还插入了第三个子层,对编码器堆栈的输出执行多头注意力。与编码器类似,我们在每个子层周围采用残差连接,随后进行层归一化,并且修改了解码器堆栈中的自注意力子层,以防止位置注意到后续位置。这种掩蔽机制,加上output embedding 向后偏移一位的,确保位置i的预测仅依赖于小于i的已知输出。
2.2 涉及到的符号说明
| symbol | 含义 |
|---|---|
| d | 模型大小 / 隐藏状态(hidden state)维度 / 位置编码大小。 |
| h | 多头注意力层中的头数。 |
| L | 输入Token序列的长度。 |
| N | 模型中注意力层的总数;不考虑 MoE。 |
| \mathbf{X} \in \mathbb{R}^{L \times d} | 输入序列,其中每个元素已映射为形状为 d 的嵌入向量,维度与模型尺寸相同。 |
| \mathbf{W}^k \in \mathbb{R}^{d \times d_k} | Key 权重矩阵。 |
| \mathbf{W}^q \in \mathbb{R}^{d \times d_k} | Query 权重矩阵。 |
| \mathbf{W}^v \in \mathbb{R}^{d \times d_v} | Value 权重矩阵。通常有d_k = d_v = d。 |
| \mathbf{W}^k_i, \mathbf{W}^q_i \in \mathbb{R}^{d \times d_k/h}; \mathbf{W}^v_i \in \mathbb{R}^{d \times d_v/h} | 每个头的权重矩阵。 |
| \mathbf{W}^o \in \mathbb{R}^{d_v \times d} | 输出权重矩阵。 |
| \mathbf{Q} = \mathbf{X}\mathbf{W}^q \in \mathbb{R}^{L \times d_k} | query embedding 输入。 |
| \mathbf{K} = \mathbf{X}\mathbf{W}^k \in \mathbb{R}^{L \times d_k} | key embedding 输入。 |
| \mathbf{V} = \mathbf{X}\mathbf{W}^v \in \mathbb{R}^{L \times d_v} | value embedding 输入。 |
| \mathbf{q}_i, \mathbf{k}_i \in \mathbb{R}^{d_k}, \mathbf{v}_i \in \mathbb{R}^{d_v} | query、key 和 value 矩阵中的行向量,\mathbf{Q}\mathbf{K}和 \mathbf{V}。 |
| S_i | query\mathbf{q}_i的第i行的一组需要关注的关键位置。 |
| \mathbf{A} \in \mathbb{R}^{L \times L} | 输入序列长度为L及其自身之间的自注意力矩阵。 \mathbf{A} = \text{softmax}(\mathbf{Q}\mathbf{K}^\top / \sqrt{d_k}) |
| a_{ij} \in \mathbf{A} | query \mathbf{q}_i和 key \mathbf{k}_j之间的标量注意力分数。 |
| \mathbf{P} \in \mathbb{R}^{L \times d} | 位置编码矩阵,其中第i行\mathbf{p}_i是输入\mathbf{x}_i的位置编码。 |
三、Transformer 详细解析
我们按照 Transformer 的流程,逐个组件进行解析
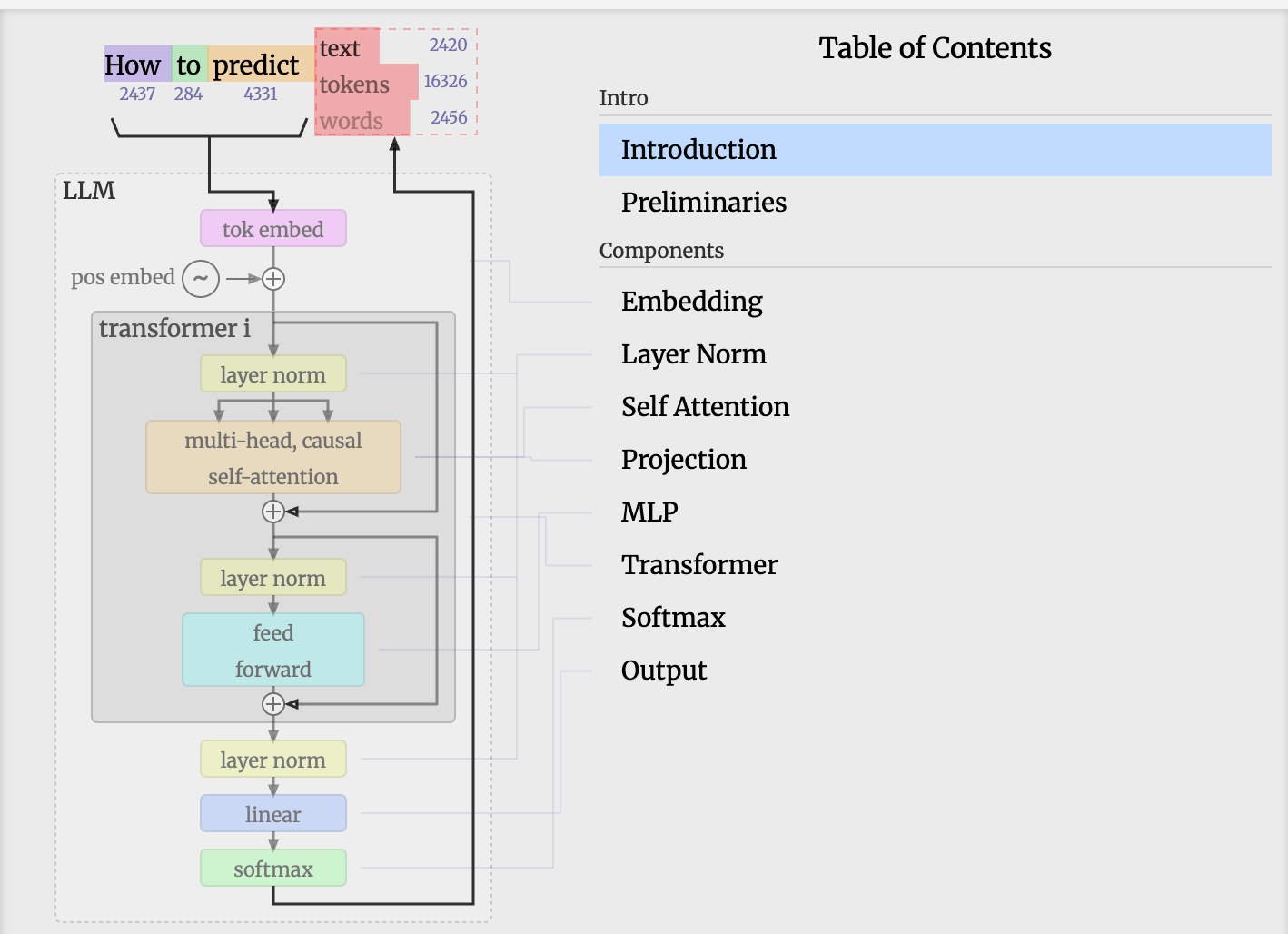
3.1 Inputs / Outputs(shifted right)——输入/输出,自然语言的预处理
要理解 Transformer 输入输出,就要先了解在 NLP 中对自然语言进行处理的基础单元——Token
3.1.1 Token——Inputs / Outputs 的基础单元
在 Transformer 模型中,Token 是指输入文本序列中被模型单独处理的最小单位,Transformer 模型的所有计算都是基于 Token 进行的。
在一些情况下,我们会将 Token 翻译为 词元,其实这个是文本模型的特例,在多模态模型中,token 可能指的是图像块、音频块、视频块,词元一词是无法准确涵盖的,所以,下文里面还是以 token 为称呼
为什么我们需要将自然语言转成 token?
计算机无法直接理解自然语言中的文本,需要先将文本划分成更易于表示、计算和学习的基本单位。
| 原因 | 作用和效果 |
|---|---|
| 文本数值化 | 计算机无法直接处理人类语言,它只能处理数字。因此需要将文本先转换成数字表示,而 **Token 就是实现这个转换的最小单位。**每个 Token 都映射到一个数值向量(Embedding),模型通过这些向量进行计算。(后续讲到) |
| 降低词汇量 | 如果不进行 token 化,而直接使用句子或段落,模型将面临极大的词汇组合量,几乎无法处理。token 化之后,大大减少了模型需要记忆的单元数量,从而大幅降低了模型训练和计算的难度。 例子: "我爱AI" 整个句子作为一个整体,模型必须分别学习每种句子组合,几乎不可能实现。token 化之后,模型只需要记忆单独的词 "我", "爱", "AI",这些词可自由组合成多种不同句子。 |
| 缓解数据稀疏 | 语言中有很多低频词或罕见组合,这些低频词汇在训练中出现频率极低,直接学习这些词汇会导致模型性能差,Token 化之后,尤其是子词分词方法(如BPE、WordPiece),能将低频词汇拆分为更常见的子单元,大幅减少数据稀疏性。 例子: "unbelievable" → ["un", "##believ", "##able"]这样模型不需要单独学习一个低频词 "unbelievable",而是通过已知的子词 "un", "##believ", "##able" 来组合生成。 |
| 处理未知词 (OOV,Out-of-Vocabulary)问题 | 语言不断变化,新词频繁出现。若模型以完整单词为单位: - 一旦遇到训练时未出现的新词,就会出现无法识别的未知词问题。 采用子词级 Token 后: - 未知词可以通过已知的子词组合表示,即便新词模型也能有效处理。 例子: "ChatGPT" → ["Chat", "##G", "##PT"] |
| 提高泛化能力 | Token 使得模型可以通过组合有限的基础单元,泛化到无限多的新句子、新组合中去。 - 模型只需学习有限数量的 Token,即可表达无限数量的句子组合。 |
| Attention机制需要 | Transformer 中的 Attention 机制要求: - 模型需要对每个输入单元计算彼此间的相关性。 - Token 正是 Attention 机制运算的基础单位,每个 Token 都会与序列中其他 Token 计算相关性。 |
如上所说,Token 是 Transformer 等 NLP 模型必不可少的基础单位,它使得模型能够高效、泛化地学习语言,并最终实现对文本的理解与生成。
那么我们如何将 自然语言转成 Token 呢?
3.1.2 Tokennizer——分词器,将自然语言转为 Token 序列
Tokenizer 就是一个将原始文本转为 token 序列 的工具。
Tokenizer 完成的基本任务包括:
-
文本切分:将文本切割成单词、子词、字符或标点等小单位(token)。
-
映射到数值:为每个 token 分配唯一的数值(ID),以便模型处理。
-
构建词汇表(vocabulary):从大量文本中统计和创建词汇表,定义所有可能的 token。
举例:
"I love NLP." -> ["I", " love", " NL", "P", "."] -> [10, 200, 300, 341, 35]
常见的 Tokenizer 类型:
| 类型 | 描述 | 常用模型 | 示例("I love playing Transformers.") |
| 单词级别 (Word-level) | 每个单词作为一个单独的 token。 简单直观,但词汇量大,容易出现未知词(OOV,Out-of-Vocabulary)问题。 | NLTK、SpaCy | ["I", "love", "playing", "Transformers", "."] |
| 子词级别 (Subword-level) 单词拆分成子词 (主流方案) | Byte-Pair Encoding (BPE) - 迭代合并最频繁出现的字符组合,生成子词表。 - 解决OOV问题,灵活性强。 | GPT-2、GPT-3、RoBERTa、GPT-Neo | ["I", "Ġlove", "Ġplaying", "ĠTransform", "ers", "."](注: Ġ代表空格) |
| WordPiece - Google 提出的子词算法,基于语言模型似然性合并字符。 - 使用前缀标记 "##" 表示子词连接。 | BERT、DistilBERT、ELECTRA 等谷歌模型。 | ["I", "love", "playing", "transform", "##ers", "."] | |
| SentencePiece - Google 开源的通用子词分词工具。 - 可支持 BPE 和 Unigram 等算法,能直接处理未经预处理的文本(不依赖外部分词)。 - https://github.com/google/sentencepiece | SentencePiece (BPE 模式) T5、LLaMA 系列 | SentencePiece (BPE 模式) ["▁I", "▁love", "▁playing", "▁Transform", "ers", "."](注: ▁代表空格) | |
| SentencePiece (Unigram 模式) XLNet、ALBERT | SentencePiece (Unigram 模式) ["▁I", "▁love", "▁play", "ing", "▁Trans", "form", "ers", "."] | ||
| Tiktoken(OpenAI 专有) - 专门为 OpenAI GPT 模型设计的分词器。 - 基于 BPE 优化,速度快,精度高,用于计算 GPT API token 数量。 - https://github.com/openai/tiktoken | GPT-3.5、GPT-4(OpenAI 官方推荐) | "I love NLP." → ["I", " love", " NL", "P", "."] | |
| 字符级别 (Character-level) | 每个字符作为一个 token,词汇量小。 几乎没有未知词问题,但序列长度会增加很多,效率较低。 | 早期字符级模型,如 Char-RNN | ["I", " ", "l", "o", "v", "e", " ", "p", "l", "a", "y", "i", "n", "g", " ", "T", "r", "a", "n", "s", "f", "o", "r", "m", "e", "r", "s", "."] |
当前大语言模型广泛使用的是 子词级别 分词器(如 BPE、WordPiece、SentencePiece)
截取一段 tokennizer 的文件发现,怎么都是乱码?
这是因为很多现代模型(例如使用 Byte-Level BPE 或 SentencePiece 的模型)的 tokenizer 并不是直接存储“中文字符”这样的形式,而是将文本先转换为字节序列,然后通过子词合并算法生成 token。这样做有时会导致输出的 token 显示为一些看起来比较“奇怪”的字符组合(例如“áıķ”),这些并非传统意义上的中文字符,而是经过编码后的表示。
"夸": 101651,
"åľĺ": 101652,
"éĿ¢ä¸Ĭ": 101653,
"æĬĸ": 101654,
"èĦĨ": 101655,
"é©°": 101656,
"ä¼IJ": 101657,
"妨": 101658,
"å®ļäºĨ": 101659,
"ç³Ĭ": 101660,
"æŃ¡": 101661,
"éĥ¨éķ¿": 101662,
"ç§ī": 101663,
"èĪĨ": 101664,
"åĪijäºĭ": 101665,
"åIJµ": 101666,
"æ¤Ĵ": 101667,
"è¡ĵ": 101668,
处理好 token 序列之后,Token 序列是如何在 Transformer 中使用和生成的呢?
3.1.3 Shifted Right(右移)—— Decoder 的输出方式
在 Transformer 中,shifted right(右移)专指在训练和推理过程中对 decoder 输入序列 的处理方式:
-
decoder 在预测第 t 个位置的 token 时,只能看到位置 t 之前的所有 token(即从第一个位置开始,到第 t-1 个位置为止)。
-
为实现这种因果关系(causal),decoder 输入序列会相较于目标输出序列向右移动一位(因此称为 shifted right)。
-
如果不进行 shifted right,decoder 在预测每个位置的 token 时都可以直接看到自己需要预测的 token,造成信息泄漏,无法训练模型的预测能力。因此,通过将目标序列向右移动一位,可以使 decoder 自然地学到序列的生成过程。
3.1.4 理解 inputs / Outputs——以翻译任务为例
Transformer 的 Decoder 通常会使用特殊符号来标记输出序列的开始和结束,但这些特殊符号的具体形式并不是固定的,不同模型或框架有不同的命名方式,常见的有:
<start>、<end>
<s>(start)、</s>(end)
<bos>(begin of sentence)、<eos>(end of sentence)
-
Inputs 代表输入的文本,比如一个翻译任务:
I love NLP,经过 encoder 一次性全局理解输入,生成输入的隐藏表示(hidden representation) -
Outputs 则代表输出的文本,逐步生成输出,每一步都需要重新 decoder 一次。逐步生成输出是符合我们使用大模型的体验的
| 步骤 | 过程 | 预测的输出 | Encoder执行 | Decoder执行 |
| 1 | 输入:I love NLP → Encoder | ❌ | ✅执行一次 | ❌ |
| 2 | Decoder 第一次输入 <bos> | 我 | ❌(使用缓存) | ✅ |
| 3 | Decoder 第二次输入 <bos> 我 | 喜欢 | ❌(使用缓存) | ✅ |
| 4 | Decoder 第三次输入 <bos> 我 喜欢 | 自然语言处理 | ❌(使用缓存) | ✅ |
| 5 | Decoder 第四次输入 <bos> 我 喜欢 自然语言处理 | <eos> | ❌(使用缓存) | ✅ |
最终的输出 我 喜欢 自然语言处理
但是这里有个问题,计算机可不理解汉字,transformer 是怎么进一步处理 Token 序列的呢?
3.2 Input / Output Embedding——词嵌入,将人类的自然语言转为计算机可以理解的语言
3.2.1 Embedding 是什么?

在 NLP(自然语言处理)领域,embedding 的概念主要用于将离散的词语或符号映射到一个连续的向量空间中,使得相似的词在向量空间中距离更近,这通常是通过机器学习得到的
还有另一个向量 Vector, 和 embedding什么关系?
从严格意义上讲,embedding 本质上就是一个 vector,但它们的用途和生成方式有所不同:
Vector:是一个数学概念,表示一个有序数值数组,可以出现在任意的连续空间中,并不一定携带特定的语义信息。
Embeddings:在机器学习和自然语言处理领域,embeddings 指的是将离散的对象(如单词、字符或其他类别)映射到一个连续向量空间中,生成的 vector 不仅仅是数值数组,而是经过训练后能够捕捉对象之间语义关系和特征的表示。常见的例子有 Word2Vec、GloVe、BERT 等生成的向量。
举例:为了描述人,我们可以通过 [身高,体重,性别] 来提取一个人特征,特征的维度越多,对这个人的描述就更具体、更清晰,如果将这个人的特征映射到坐标系中,则可以发现 特征相近的 向量,往往距离更近
那么 ,Transformer 架构是如何进行 embedding 的呢?
3.2.2 Lookup Table / Embedding Matrix——查找表 / 嵌入矩阵,Token 快速转化为 embedding
承接我们对 上一小节 Token 的理解,我们使用 tokenizer 将自然语言处理成了 token 序列,可以发现,经过分词,token 是可以枚举的,总量就是这么多,那岂不是我提前训练好每个 token 的 embedding,在使用时通过查表就可以获取到 token 的 embedding 了?
实际上,目前所有主流的 Transformer 架构都是这么做的,就是通过 Lookup Table(查找表)来进行 token 的 embedding
每一个 token(词或子词)都有一个对应的向量表示,所有 token 的向量组成一个「查找表」(也就是一个矩阵)。
只要你给我 token 的 ID,我就能从这个矩阵中查到它的向量表示。
Embedding Matrix 嵌入矩阵 的公司如下:
{E} \in \mathbb{R}^{V \times d}
-
V:Vocabulary Size(词汇表大小):这是指模型中所有词汇(或类别)的总数。每个词或类别都会对应嵌入矩阵中的一行,因此矩阵的行数就是词汇表的大小。
-
d:Embedding Dimension(嵌入向量的维度):这是指每个词对应的向量的长度。这个值通常是一个超参数,选择时需要考虑模型的复杂度、任务需求以及数据规模。常见的维度有 50、100、300、768 等。
-
在实际应用中,嵌入维度的选择往往需要通过实验来验证最佳效果,同时也要考虑到计算资源和模型的泛化能力。
例子:
假设词表中有:
Vocabulary = ["我", "爱", "AI"]
词向量维度 𝑑 = 4, 那么 Embedding Matrix E 就可能是:
"我" → [0.1, 0.3, -0.2, 0.5]
"爱" → [0.4, 0.7, 0.1, 0.2]
"AI" → [-0.3, 0.9, 0.0, -0.4]
输入 token 的 ID 为 1("爱"),就直接查找第1行向量作为它的 embedding。
3.2.3 查找表 / 嵌入矩阵的值是怎么得到的?
Embedding Matrix 是模型参数的一部分,和 Transformer 的所有参数(如注意力层、前馈层等)一起,通过统一的损失函数、优化器、反向传播一起被训练。
模型训练 = 更新整个参数集合,包括:
-
✔️ Embedding 层参数(查找表)
-
✔️ Transformer 层参数(Attention、LayerNorm、Feed Forward 等)
-
✔️ output projection层参数(输出投影层,通常使用嵌入矩阵转置)
-
❌ 不训练:tokenizer(静态预处理)
整体流程:\text{Input token ID} \xrightarrow{\text{Embedding}} \xrightarrow{\text{Transformer}} \xrightarrow{\text{Output Projection}} \xrightarrow{\text{Loss}} \xrightarrow{\text{Backpropagation}}
Embedding 只是这个大函数中的「第一层」,它也跟后面几层一起更新。
如上,我们将每个 token 转成了计算机语言 embedding , Transformer 是如何进行进一步处理的呢?
3.3 Attention?Attention!
https://lilianweng.github.io/posts/2018-06-24-attention
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA https://kexue.fm/archives/10091
Attention 是 Transformer 架构的核心,我们先理解 Attention 是什么
注意力在某种程度上受到我们如何将视觉焦点集中在图像的不同区域或关联句子中的单词的启发

人类的视觉注意力使我们能够以“高分辨率”(例如,观察黄色框中的尖耳朵)聚焦于某一区域,同时以“低分辨率”感知周围图像(例如,雪地背景和服装如何?),并据此调整焦点或进行推理。给定图像的一小块区域,其余部分的像素为应展示的内容提供了线索。我们期望在黄色框中看到一只尖耳朵,因为我们已经看到了狗的鼻子、右侧的另一只尖耳朵以及柴犬神秘的眼睛(红色框中的部分)。然而,底部的毛衣和毯子就不如那些犬类特征能够提供帮助。
同样地,我们可以解释同一句话或近似上下文中单词之间的关系。当我们看到“eating”时,我们期望很快出现与食物相关的词语。颜色词描述的是食物,但可能并不直接与“eating”关联。同一句中,一个单词对其他单词的“attends to”方式各不相同。
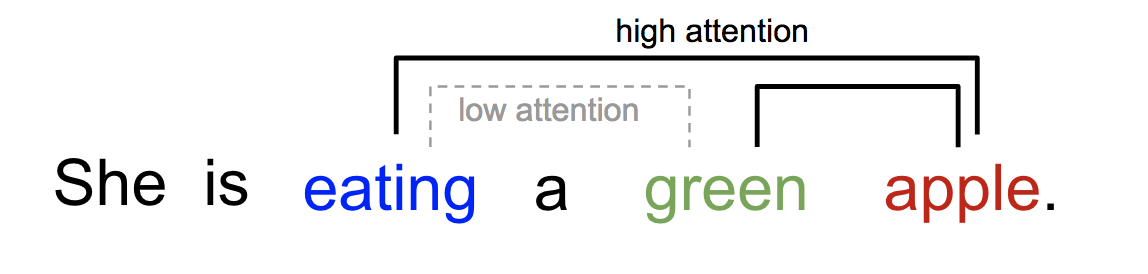
深度学习中的注意力可以广义地理解为一组重要性权重向量:为了预测或推断一个元素,比如图像中的像素或句子中的单词,我们利用注意力向量来估计它与其他元素之间的关联强度(或者正如你在许多论文中读到的那样称为“attends to”),并将这些元素的值按注意力权重加权求和,作为对目标的近似。
要了解 attention究竟做了什么,我们需要了解 Transformer 之前的架构——seq2seq(Sequence to Sequence)
3.3.1 Attention出现的原因—— Seq2seq 模型遇到的长难句问题
seq2seq 首发论文:https://arxiv.org/abs/1409.3215
seq2seq 是openai 创始人 Ilya Sutskever 提出的一种encoder-decoder 架构的神经网络模型,它旨在将一个输入序列(源)转换为一个新序列(目标),且两个序列的长度可以是任意的。转化任务的示例包括文本或音频形式的多语言机器翻译、问答对话生成等
-
**encoder(编码器)**处理输入序列,并将信息压缩成一个固定长度的上下文向量,也称为句子嵌入(sentence embedding )或“思维”向量(“thought” vector)。这种表示预期能很好地总结整个源序列的含义。
-
**decoder(解码器)**以上下文向量进行初始化,以生成转换后的输出。早期工作仅使用编码器网络的最后状态作为解码器的初始状态。
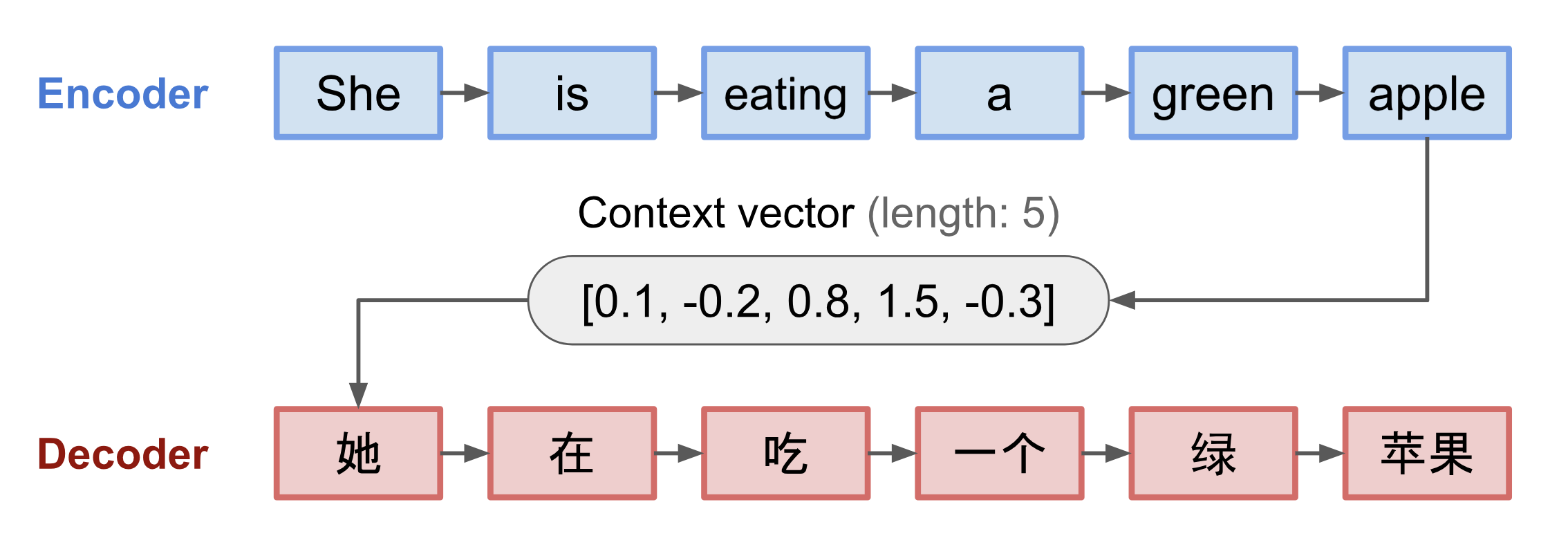
这种方法存在两个主要问题(长难句):
-
**信息瓶颈问题(Information Bottleneck):**当输入句子较长或信息量较大时,固定长度的 vector 无法有效容纳所有关键信息,导致信息丢失,从而影响模型性能。
-
**长距离依赖问题(Long-distance Dependencies):**在处理长序列时,传统方法难以捕捉远距离单词之间的关系,影响对语义的全面理解。
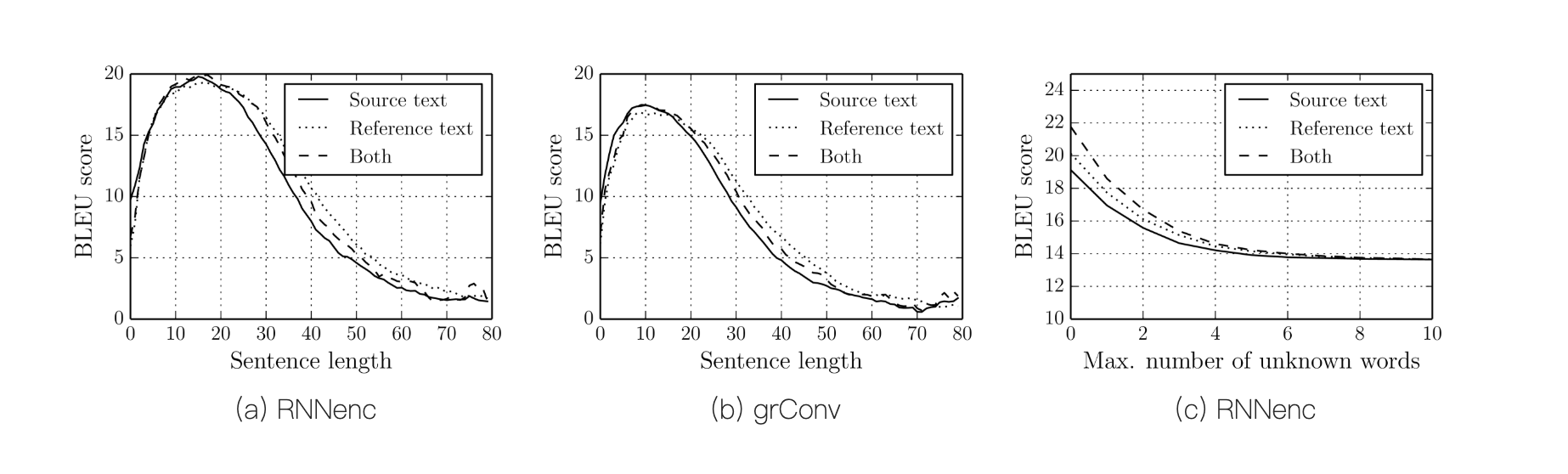
对 seq2seq 模型 长难句问题的定量分析:
https://arxiv.org/abs/1409.1259
BLEU(Bilingual Evaluation Understudy)是一种自动评价机器翻译系统质量的指标,BLEU 的得分一般在 0 到 1 之间,通常会乘以 100 表示成百分制。得分越高,表示机器翻译结果与参考翻译越接近,质量越好。
RNNenc 模型是 seq2seq 架构的训练模型
传统seq2seq 模型在长难句上遇到的这些问题,我们应该如何解决?
3.3.2 Attention的出现——联合学习对齐与翻译
Neural Machine Translation by Jointly Learning to Align and Translate:https://arxiv.org/abs/1409.0473
没有 NLP 经历的人在理解 Attention 时经常会有困惑,为什么Attention 会用在神经网络中?其实 NLP 在 Transformer 诞生之前一直在持续发展,很多概念都是 NLPer 过往的积累,所以我们直接看 Attention 的首发论文,就能理解这个概念了。
在 Attention 的首发论文中,Bahdanau 还没有将这个机制称为 attention,而是 Jointly Learning to Align and Translate (联合学习对齐与翻译)这基本就是 Attention 机制的表示了,我们直接看原文:
A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This may make it difficult for the neural network to cope with long sentences, especially those that are longer than the sentences in the training corpus.Choet al.(2014b)showed that indeed the performance of a basic encoder–decoder deteriorates rapidly as the length of an input sentence increases.
In order to address this issue, we introduce an extension to the encoder–decoder model which learns to align and translate jointly. Each time the proposed model generates a word in a translation, it(soft-)searchesfor a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words.
The most important distinguishing feature of this approach from the basic encoder–decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector. We show this allows a model to cope better with long sentences.
这种编码器–解码器方法的一个潜在问题在于,神经网络需要能够将源句子的所有必要信息压缩到一个固定长度的向量中。这可能会使神经网络难以处理长句子,尤其是那些比训练语料中句子更长的句子。Cho 等人(2014b)表明,随着输入句子长度的增加,基本编码器–解码器模型的性能确实会迅速恶化。
为了解决这一问题,我们引入了对编码器–解码器模型的一个扩展,该扩展学习实现对齐与翻译的联合进行。每当该模型在翻译中生成一个单词时,它就会(软)搜索源句子中最集中的一组与该单词最相关的信息位置。随后,模型基于与这些源位置相关联的上下文向量以及所有之前生成的目标单词来预测一个目标单词。
这种方法与基本的 encoder–decoder 模型最重要的区别在于,它并不试图将整个输入句子编码成一个固定长度的向量。相反,它将输入句子编码为向量序列,并在翻译解码过程中自适应地选择这些向量中的一个子集。这样,神经翻译模型就不必将源句子的所有信息(无论其长度如何)挤压进一个固定长度的向量中。我们证明这使得模型能够更好地处理长句子。
Additive Attention(加性注意力)
\text{score}(\boldsymbol{s}_t, \boldsymbol{h}_i) = \mathbf{v}_a^\top \tanh(\mathbf{W}_a[\boldsymbol{s}_{t-1}; \boldsymbol{h}_i])
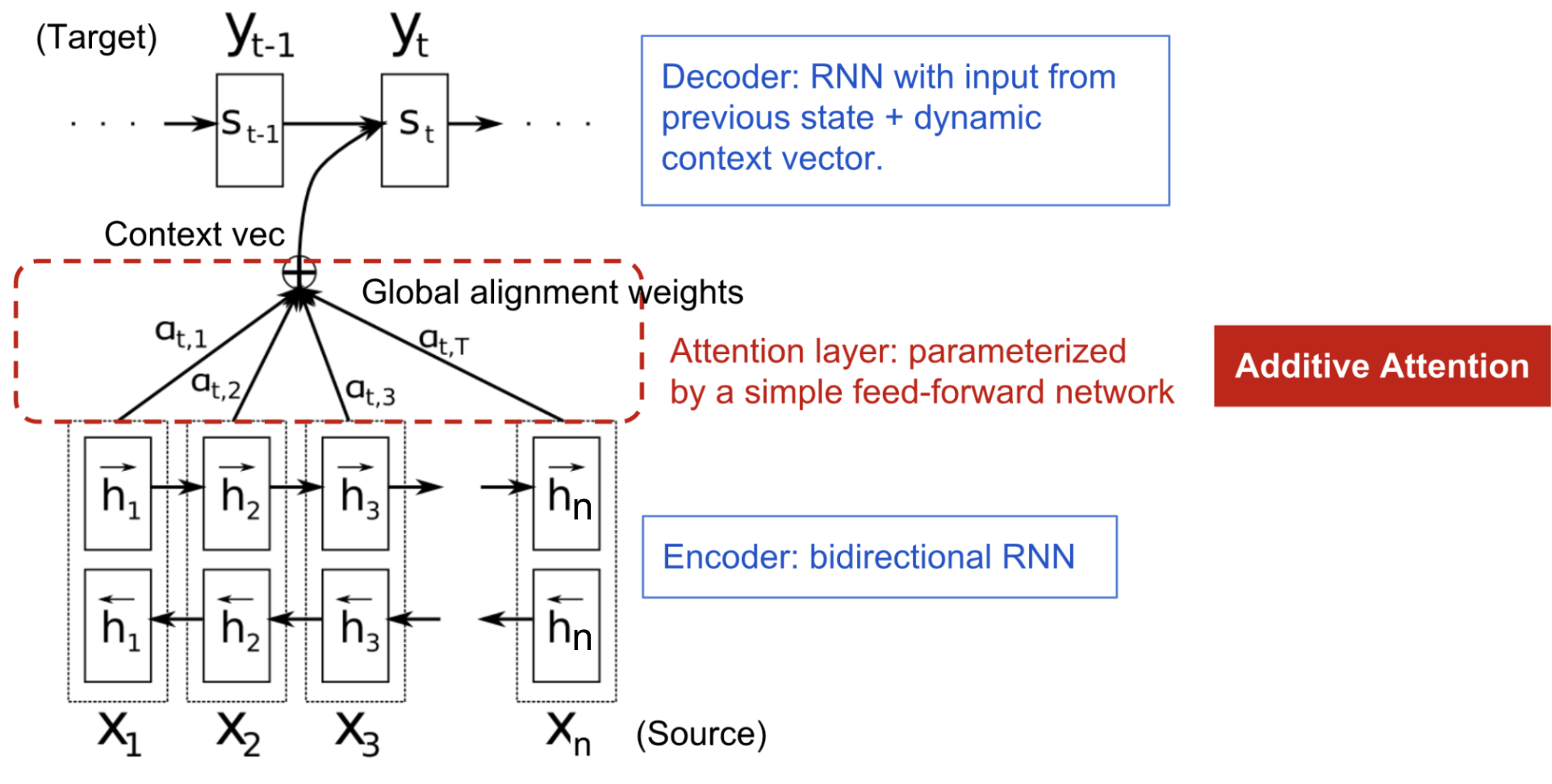
很快,联合学习对齐与翻译被人们以更好概括这项技术的概念来包装了,Attention 就出现了
3.3.3 Attention 的效果——解决长难句问题
以下是 Bahdanau 在 Neural Machine Translation by Jointly Learning to Align and Translate 中使用 Additive 的实验结果。
我们列出了按照 BLEU 分数衡量的翻译性能。从表中可以明显看出,在所有情况下,所提出的 RNNsearch 都优于传统的 RNNencdec。更重要的是,当只考虑由 已知单词构成的句子时(No UNK),RNNsearch 的性能与传统的基于短语的翻译系统 (Moses) 一样高。这是一项重大成就,鉴于 Moses 除了我们用来训练 RNNsearch 和 RNNencdec 的平行语料库之外,还使用了一个独立的单语语料库 (418M words)。
RNNencdec 为不使用 联合学习对齐与翻译 技术的 模型
RNNsearch 是使用了联合学习对齐与翻译 技术的 模型
然后对每个模型进行了两次训练:
首先使用句子长度最多为 30 个单词的句子(RNNencdec-30,RNNsearch-30),
然后使用句子长度最多为 50 个单词的句子(RNNencdec-50,RNNsearch-50)。
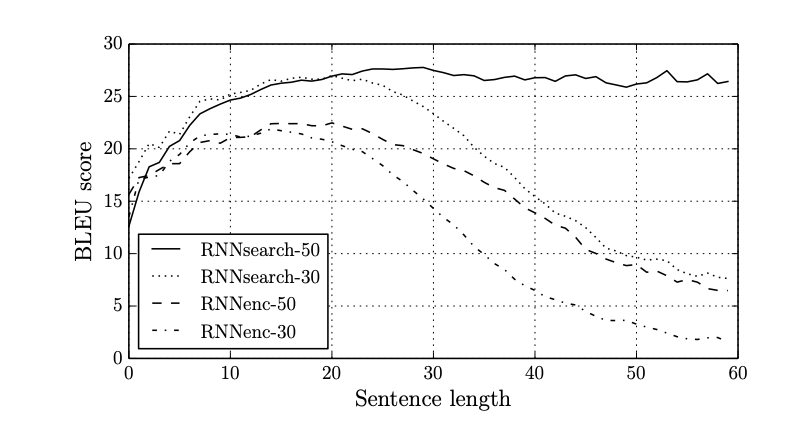
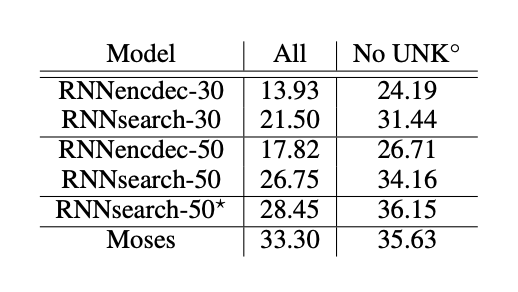
我们看到 Attention 机制基本解决了以往遇到的 长难句问题。
3.3.4 Attention机制的选择
借助注意力机制,源序列和目标序列之间的依赖关系不再受中间距离的限制,鉴于注意力机制在机器翻译中的巨大改进,人们也开始探索各种其他形式的注意力机制,下面是几个流行的注意力机制及其对应的对齐分数函数的概要表:
| 名称 | 对齐分数函数 | 论文 |
| Content-base attention | \text{score}(\boldsymbol{s}_t, \boldsymbol{h}_i) = \text{cosine}[\boldsymbol{s}_t, \boldsymbol{h}_i] | Graves2014 |
| Additive | \text{score}(\boldsymbol{s}_t, \boldsymbol{h}_i) = \mathbf{v}_a^\top \tanh(\mathbf{W}_a[\boldsymbol{s}_{t-1}; \boldsymbol{h}_i]) | Bahdanau2015 |
| Location-Base | \alpha_{t,i} = \text{softmax}(\mathbf{W}_a \boldsymbol{s}_t) | Luong2015 |
| General | \text{score}(\boldsymbol{s}_t, \boldsymbol{h}_i) = \boldsymbol{s}_t^\top\mathbf{W}_a\boldsymbol{h}_i where Wa is a trainable weight matrix in the attention layer. | Luong2015 |
| Dot-Product | \text{score}(\boldsymbol{s}_t, \boldsymbol{h}_i) = \boldsymbol{s}_t^\top\boldsymbol{h}_i | Luong2015 |
| Scaled Dot-Product | \text{score}(\boldsymbol{s}_t, \boldsymbol{h}_i) = \frac{\boldsymbol{s}_t^\top\boldsymbol{h}_i}{\sqrt{n}} | Vaswani2017 |
Transformer 最后选择了Scaled Dot-Product Attention(点积缩放注意力),是出于什么考量呢?
Transformer 的论文里有解释:
最常用的两种注意力函数是加性注意力 (Additive)和点积(Dot-Product)注意力。点积注意力与我们的算法完全相同,只是增加了一个缩放因子 \frac 1 {\sqrt{d_k}} 。加性注意力通过一个带单隐藏层的前馈网络计算兼容性函数。虽然两者在理论复杂度上相似,但在实际操作中,点积注意力更快且更节省空间,因为它可以利用高度优化的矩阵乘法代码实现。
那为什么要加一个缩放因子呢?
对于小的 d_k值,两个机制的表现相似,但对于较大的d_k值,加性注意力的表现优于未进行缩放的点积注意力。我们怀疑对于大的d_k值,点积的结果会变得很大,从而将 softmax 函数推入梯度极小的区域。为了解决这一问题,我们将点积结果缩放为\frac 1 {\sqrt{d_k}} 。
接下来,我们一起探索一下 Scaled Dot-Product Attention(点积缩放注意力)的原理
3.3.5 Attention 的原理
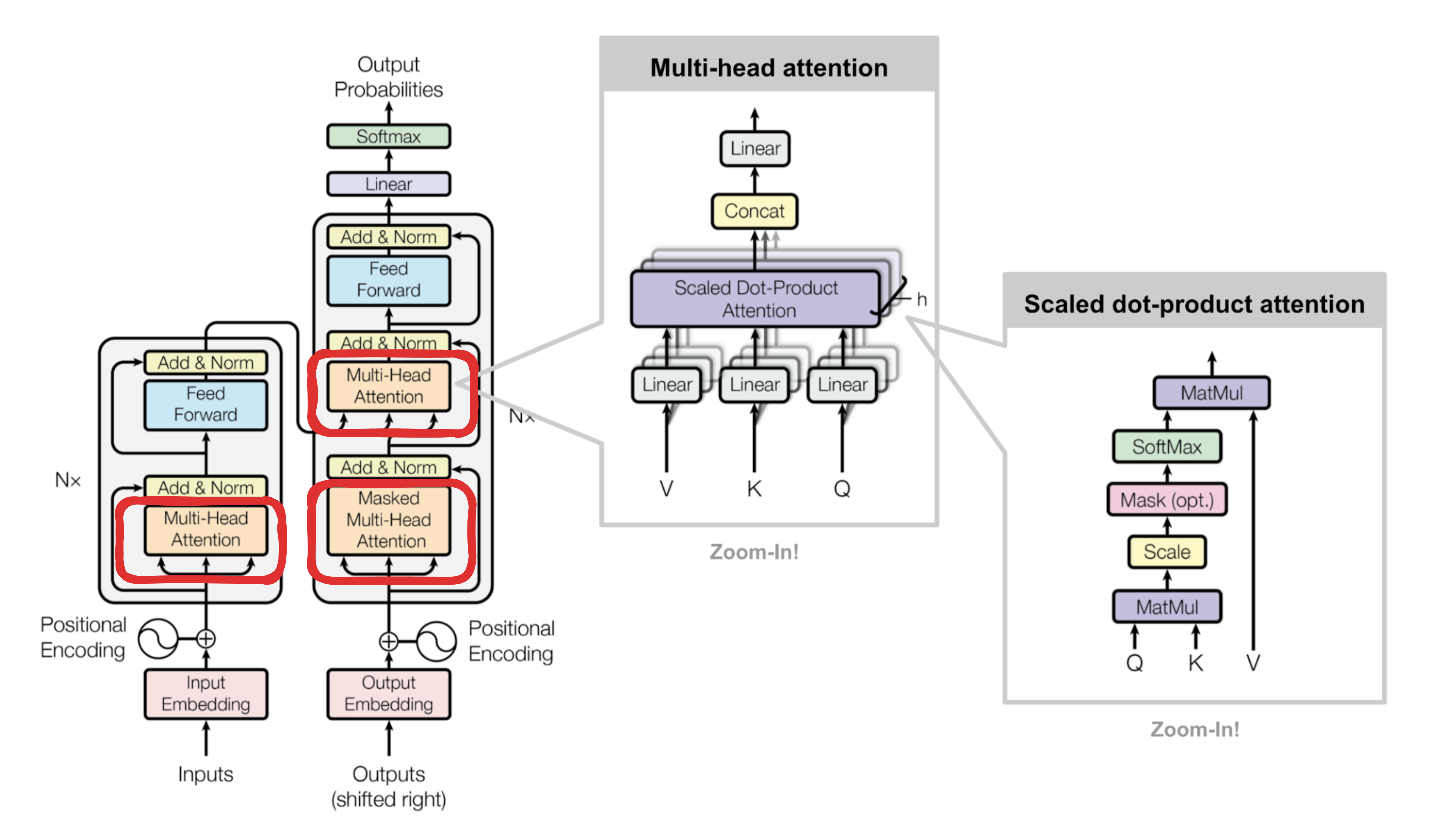
Attention 的流程就是将输入Token embedding 经过线性变换生成 Query、Key、Value,然后进行 Attention 计算(利用 Query 与 Key 的相似度计算权重,再用这些权重对 Value 进行加权求和),最终输出整合后的信息。核心就是在 Query 与 Value 之间加了一层 Key 来进行权重的计算。
Query、Key、Value的生成
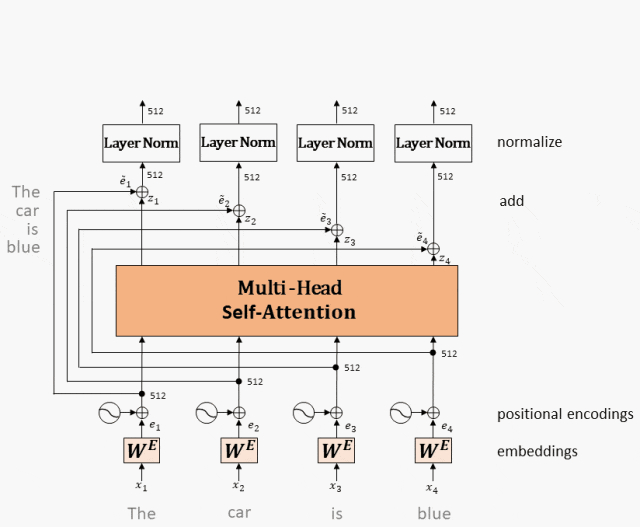
Token embedding 是对输入 token 的初步向量表示,而 query、key 和 value 则是从这些 token embedding 中通过线性变换(也就是矩阵乘法)得到的。具体关系如下:
- Token Embedding:
-
-
每个 token 经过嵌入层(embedding layer)后,会被映射为一个固定维度的向量。
- 通常这个嵌入向量还会与 positional embedding 相加,以保留位置信息。
-
- 生成 Q、K、V:
-
-
将 token embedding 输入到三个不同的线性变换层中(各自对应 W_Q、W_K、W_V,这三个权重矩阵是通过训练得到的)。
- 通过这些线性变换,得到对应的 query、key 和 value 向量:Q = \text{Token Embedding} \times W_Q,K = \text{Token Embedding} \times W_K,V = \text{Token Embedding} \times W_V
-
- 作用:
-
-
Query(查询):用于与 key 做比较,计算相似度或相关性。
-
Key(键):提供对比基础,用来判断每个 token 对当前查询的重要性。
-
Value(值):包含实际的信息内容,最终通过加权求和得到 attention 的输出。
-
-
因此,token embedding 提供了输入的基础表示,而 query、key 和 value 则是这些表示经过不同权重矩阵变换后,用于实现 attention 机制中动态上下文信息整合的关键组成部分。
举例说明:
假设我们有两个 token,经嵌入层得到的 token embedding 为二维向量:
-
Token 1 的 embedding:x_1 = [1, 2]
-
Token 2 的 embedding:x_2 = [3, 4]
将它们堆叠成一个矩阵 X(每一行对应一个 token 的 embedding):
X = \begin{bmatrix}1 & 2 \\3 & 4\end{bmatrix}
现在,我们希望生成维度也为 2 的 Query、Key 和 Value。为此,我们需要定义三个不同的权重矩阵 W_Q、W_K、W_V来实现线性变换。
假设选用以下权重矩阵:
-
Query 的权重矩阵:W_Q = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}(这里用的是 Identity 矩阵,意思是不做改变)
-
Key 的权重矩阵:W_K = \begin{bmatrix} 2 & 0 \\ 0 & 2 \end{bmatrix}(将每个维度放大 2 倍)
-
Value 的权重矩阵:W_V = \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}
计算过程
- **计算 Query,**通过矩阵乘法计算:
Q = X \times W_Q = \begin{bmatrix}1 & 2 \\3 & 4\end{bmatrix} \times \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} = \begin{bmatrix}1 & 2 \\3 & 4\end{bmatrix}
这里因为W_Q为单位矩阵,所以Q与原始 embedding 相同。
- **计算 Key,**通过矩阵乘法计算:
K = X \times W_K = \begin{bmatrix}1 & 2 \\3 & 4\end{bmatrix} \times \begin{bmatrix} 2 & 0 \\ 0 & 2 \end{bmatrix}
计算每个元素:
第一行:[1\times2 + 2\times0,\;\; 1\times0 + 2\times2] = [2, 4]
第二行:[3\times2 + 4\times0,\;\; 3\times0 + 4\times2] = [6, 8]
因此,K = \begin{bmatrix}2 & 4 \\6 & 8\end{bmatrix}
- **计算 Value,**同样进行矩阵乘法:
V = X \times W_V = \begin{bmatrix}1 & 2 \\3 & 4\end{bmatrix} \times \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}V=X×W
计算每个 token 的结果:
第一行:[1\times1 + 2\times1,\;\; 1\times1 + 2\times1] = [3, 3]
第二行:[3\times1 + 4\times1,\;\; 3\times1 + 4\times1] = [7, 7]
- 得到:V = \begin{bmatrix}3 & 3 \\7 & 7\end{bmatrix}
不理解的话,举一个更通俗的例子,我们把这个过程想象成调配果汁:
-
原始材料(Token Embedding):假设你有一篮子水果,比如苹果、香蕉和橙子,这些水果就相当于原始的 token embedding,里面包含了所有的基本信息。
-
调配机器(线性转换):现在,你有三台不同的果汁机,每台果汁机都有自己的专用配方(也就是对应的权重矩阵)。这三台果汁机分别负责制作 Query、Key 和 Value 果汁:
-
-
Query 果汁机(W_Q):这台机器会按照一种特定的比例混合水果,使得混合后产生的果汁更强调某种特定口味,比如特别突出苹果的酸甜味。这个过程就相当于把原始水果(token embedding)经过 W_Q 这个线性转换,得到一个 Query 表示,告诉你“当前你最想要的味道是什么”。
-
Key 果汁机(W_K):这台机器会把水果按另一种配方混合,可能会更均衡地反映每种水果的基本特征,好比给每种水果打上明显的标签,方便你后续比较。经过 W_K 线性转换后,你得到的 Key 表示,就像每种水果的“身份标签”,可以用来和 Query 对比。
-
Value 果汁机(W_V):这台机器的配方则保留了水果的原始风味和细节,让你在最终品尝时能感受到水果本身的丰富口感。通过 W_V 线性转换后得到的 Value 表示,就像是一杯完整的果汁,包含了所有水果的细节信息。
-
-
- 整体流程:
-
-
原始水果经过不同的果汁机(线性转换)变成了三种不同“口味”的果汁(Query、Key、Value)。
- 当你想要找到最适合你当前需求的那杯果汁时,你会先根据你想要的味道(Query)去和每杯果汁的标签(Key)对比,然后根据匹配结果决定最终选哪杯(即对 Value 进行加权整合)。
-
线性转换就像是一台调配机器,它用特定的配方(权重矩阵)重新混合原始材料(token embedding),生成适合不同用途的新表示(Query、Key 和 Value)。这样,虽然原材料中包含了所有信息,但通过不同的调配方式,我们可以得到专门用于“提问”、“匹配”和“回答”的三种风味,从而让整个 Attention 机制更有针对性和灵活性。
理解了 Q、K、V的实现,我们就到了理解注意力函数的时候了!
注意力机制的实现——Scaled Dot-Product Attention(缩放点积注意力)
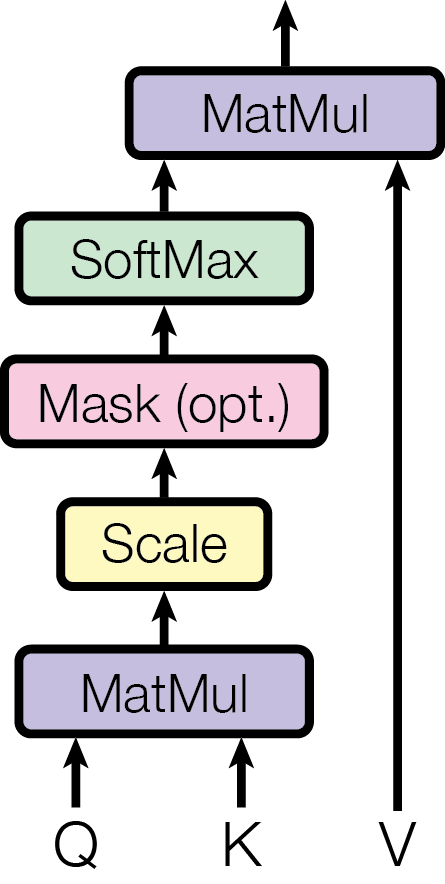
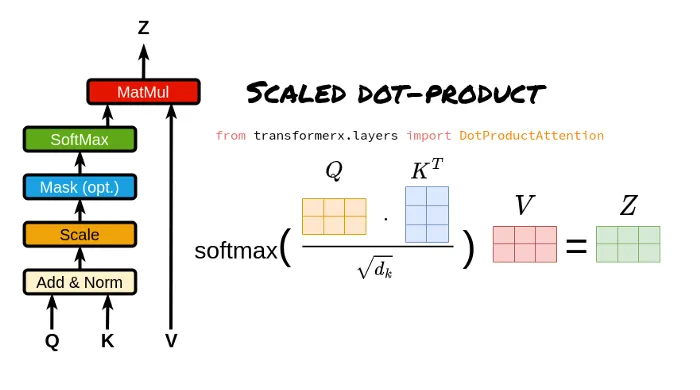
对于 Transformer 的注意力函数,我们会看到如下公式:
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V
拆解 Attention 公式得到如下步骤:
-
MatMul (Q 与K^T相乘)
-
Scale(除以 \sqrt{d_k})
-
Mask(可选,为了避免模型看到将来要预测的词,对未来时刻的 token 做遮盖,通常会在分数矩阵上对无效位置加一个很大的负数(例如-10^{9}),这样经过 Softmax 后,这些位置的权重几乎变为 0)
-
Softmax(将分数转为概率分布)
-
MatMul(用注意力权重 \alpha 与 V 相乘)
对应的理解:
\mathrm{Attention}(Q, K, V) = \underbrace{\text{softmax}\!\Big(\underbrace{\frac{Q K^T}{\sqrt{d_k}}}_{\text{MatMul +Scale}}\;+\;\text{Mask}\Big)}_{\text{SoftMax}}\;\times\;\underbrace{V}_{\text{MatMul}}
由于Q、K、V 都是矩阵,所以我们看起来不太好理解,我们拆解出单个向量的注意力权重计算公式来看,就会直观很多
对于Qyery和Key向量\mathbf{q}_i, \mathbf{k}_j \in \mathbb{R}^d(Qyery和Key矩阵中的行向量),我们可以得到一个标量得分:
a_{ij} = \text{softmax}(\frac{\mathbf{q}_i {\mathbf{k}_j}^\top}{\sqrt{d_k}})= \frac{\exp(\frac{\mathbf{q}_i {\mathbf{k}_j}^\top}{\sqrt{d_k}})}{ \sum_{r \in \mathcal{S}_i} \exp(\frac{\mathbf{q}_i {\mathbf{k}_r}^\top}{\sqrt{d_k}}) }
其中\mathcal{S}_i是第i个查询需要Attention的一组 key
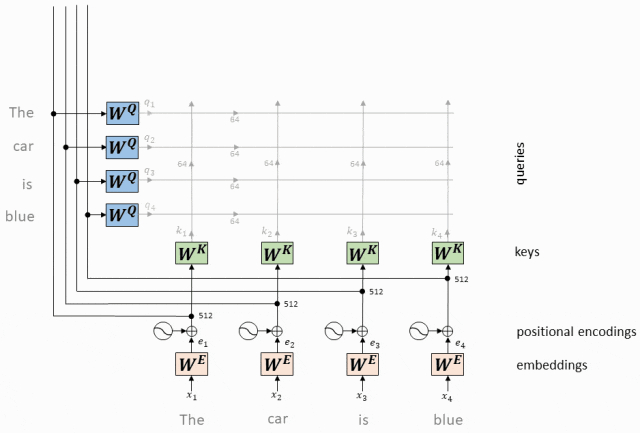
这个得分可以理解为 {q}_i向量与{k}_j向量的关注程度,{q}_i与 Key 矩阵的需要Attention 的向量都计算之后,可以得到一个对每个 key 关注程度的 概率分布[a_{i1},a_{i2},...,a_{in}],用这个概率分布和 Value 矩阵相乘,就能得到最后的 embedding,这个 embedding 就是经过注意力计算后的Token 的 embedding。
例子:
- 设 d_k=2(即 Key 的维度为 2),则缩放因子为 \sqrt{2}\approx1.414。
定义:
-
Query:Q = [1,\, 0](1×2 向量)
-
Keys:K_1 = [1,\, 0]K_2 = [0,\, 1]拼接成矩阵:K = \begin{bmatrix}1 & 0 \\0 & 1\end{bmatrix}
-
Values:V_1 = [10,\, 0]V_2 = [0,\, 10]拼接成矩阵:V = \begin{bmatrix}10 & 0 \\0 & 10\end{bmatrix}
- 计算 QK^T
计算点积:QK^T = [1,\,0] \begin{bmatrix}1 & 0 \\0 & 1\end{bmatrix} = [1\times1+0\times0,\quad 1\times0+0\times1] = [1,\, 0]
- 缩放
除以 \sqrt{2}:\frac{QK^T}{\sqrt{d_k}} = \left[\frac{1}{1.414},\, \frac{0}{1.414}\right] \approx [0.707,\, 0].
- Softmax
先计算指数:e^{0.707}\approx 2.028e^{0}=1
归一化得到权重:\alpha_1 = \frac{2.028}{2.028+1} \approx \frac{2.028}{3.028}\approx0.67,\quad\alpha_2 = \frac{1}{3.028}\approx0.33.
- 加权求和得到输出
利用权重对 Value 加权求和:\text{Attention}(Q, K, V) = \alpha_1 \cdot V_1 + \alpha_2 \cdot V_2 \approx 0.67 \times [10,\, 0] + 0.33 \times [0,\, 10].
计算:0.67\times[10,\,0]=[6.7,\,0],\quad 0.33\times[0,\,10]=[0,\,3.3].
相加得到:[6.7,\,0] + [0,\,3.3] = [6.7,\,3.3].
整个 Attention 计算过程为:
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{[1,0]\begin{bmatrix}1&0\\0&1\end{bmatrix}}{1.414}\right) \begin{bmatrix}10&0\\0&10\end{bmatrix} \approx [6.7,\,3.3]
为什么会有KVCache?
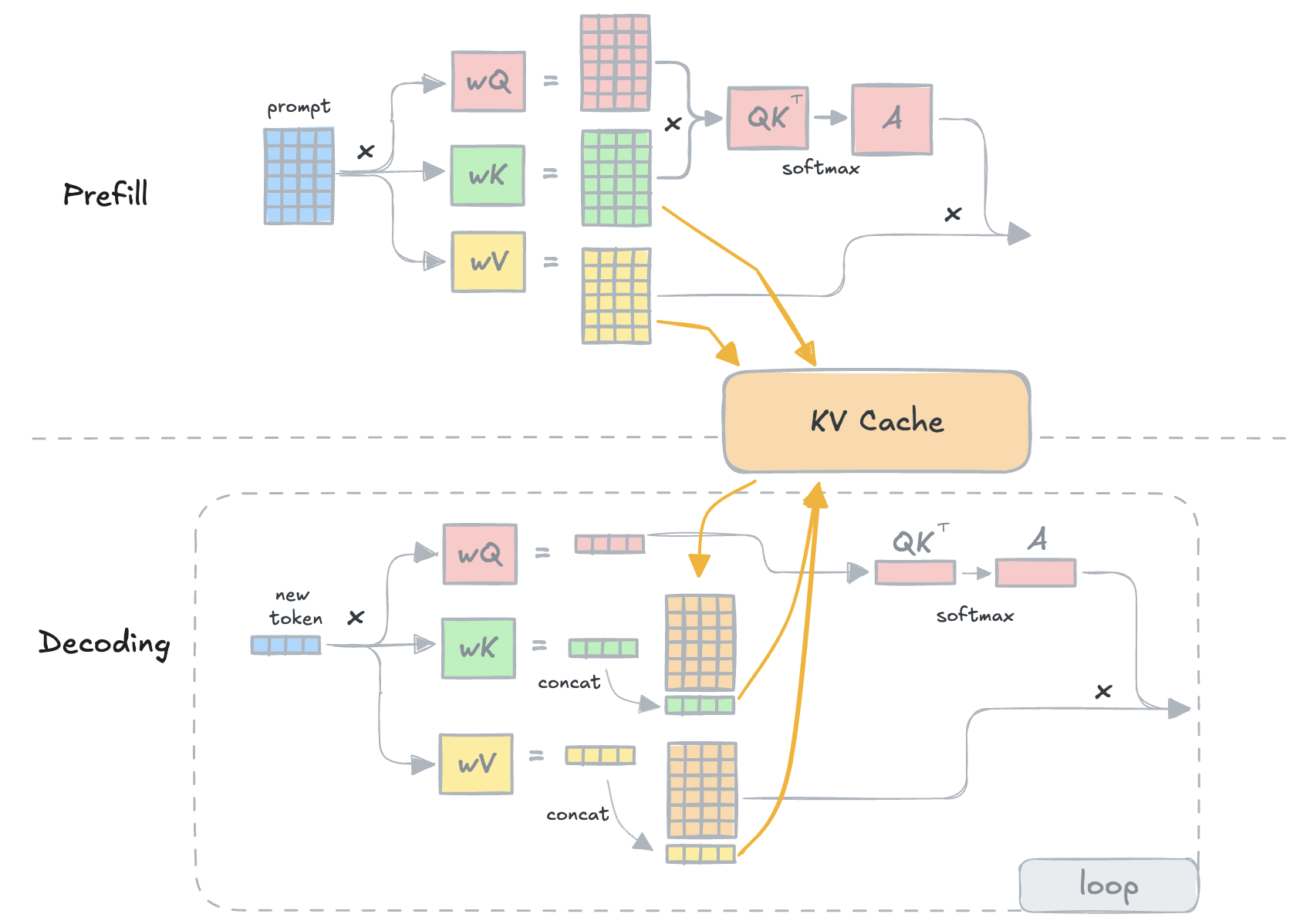
KVCache 顾名思义就是 Key Value矩阵 进行了缓存。由 Attention 计算公式我们可以看到,当生成新 token 时,模型会先将该 token 的 embedding 输入到相应的线性层中,同时生成它的 query、key 和 value。每个 Token 进行推理 attention 推理时,需要与之前的 Token 的 key 进行点积计算。
所以,每个 Token 的 q 只在当次计算 Attention 的时候使用,所以不需要保存,而 Key 和 Value 后面还会参与计算,所以需要缓存起来。
为什么要进行 softmax ?
-
归一化权重:它将原始的相似度分数(可能是任意实数)转换成一个概率分布,使得所有的权重非负且和为1。这意味着每个 Key 对应的权重可以被解释为“关注的程度”。
-
平滑处理:Softmax 可以平滑地放大较大的分数、压缩较小的分数,确保最相关的 Key 获得较高权重,同时也保留其他 Key 的信息。这有助于模型在不同情景下做出更平衡的决策。
-
方便梯度计算:Softmax 是可微的,这使得在反向传播时可以计算梯度,从而有效地训练模型。
比如一个 Query 与两个 Key 计算得到的相似度分数分别为[0.707, 0],如果直接使用这些分数作为权重,那么我们无法保证它们非负且和为1。通过 Softmax,将其转换为 [0.67, 0.33],这样每个 Key 的权重都可以看作该 Key 对当前 Query 的“匹配度”,并且便于加权求和得到最终输出。
Softmax 让 Attention 能够将各 Key 的相似度转化为一个合理的概率分布,从而指导模型“关注”最相关的信息。
必须是 softmax 么?
当然,也并非除了 Softmax 其他的函数就用不了,详细可以看下
3.3.6 Self Attention——自注意力
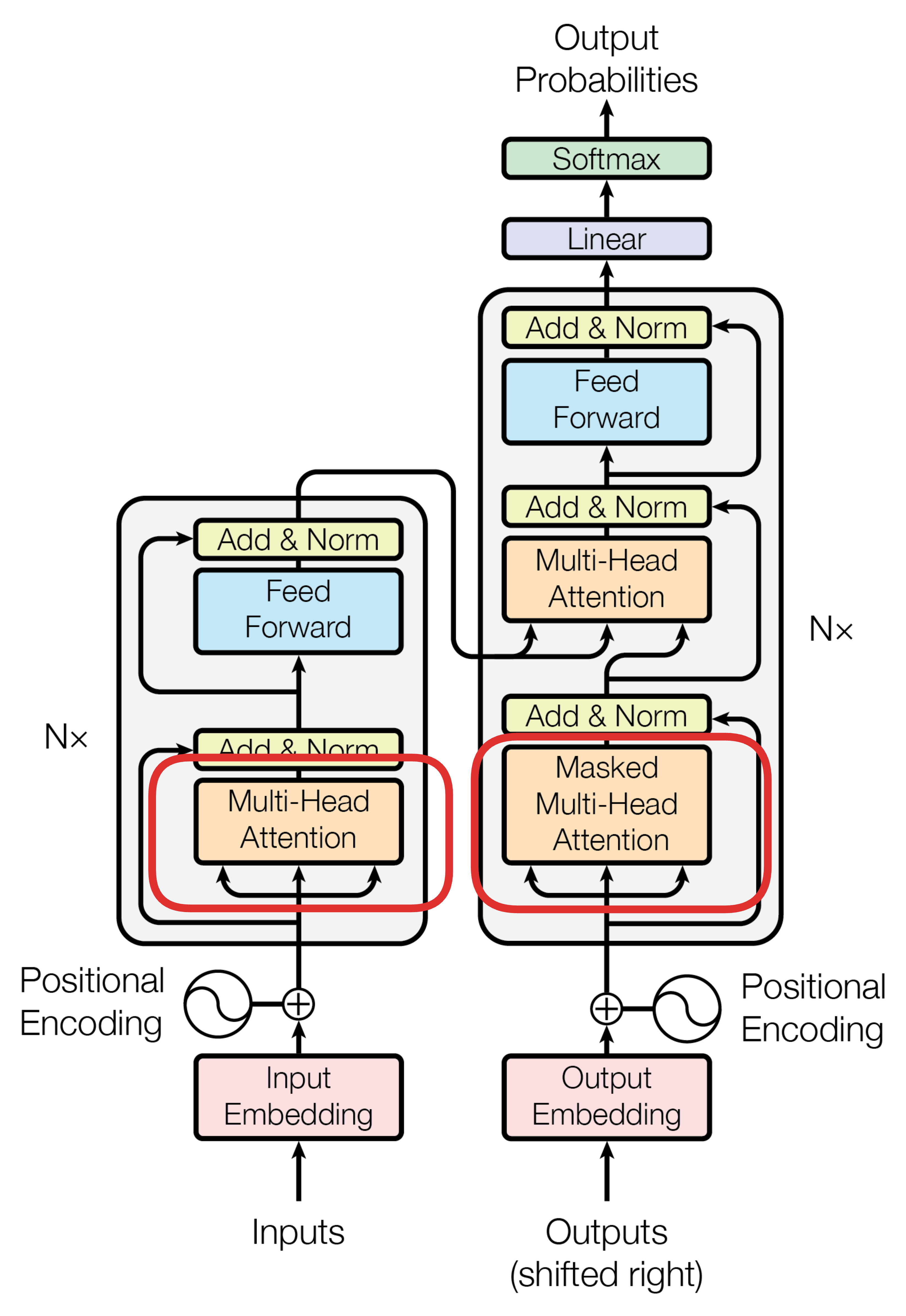
Self-Attention 指的是 Query、Key 和 Value 都来自同一个输入。也就是说,在 Self-Attention 中,输入序列中的每个 token 都会生成自己的 Query、Key 和 Value,然后这些向量用于计算序列内部各个 token 之间的相关性。这样,每个 token 就能融合整个序列的信息来构建自己的新表示。
在 Transformer 架构中,Encoder 和 decoder 的输入层使用了 self-attention
3.3.7 不同位置的 Attention 的区别
在标准 Transformer 架构中,一共有三处 Attention 机制,它们各自的输入来源、Mask 策略和作用都略有不同。
Padding 介绍
- 什么是 ?
在自然语言处理(NLP)中,<pad>(padding token)是一种特殊符号,用于将长度不一的句子或序列填充(padding)到同一固定长度。
- 为什么要 Padding?
大多数深度学习框架(如 PyTorch、TensorFlow)在一个 batch 里,要求每个样本的输入张量维度一致,才能批量并行计算(batch processing)。
但真实数据中,不同句子的 token 数量通常不相同。为了统一长度,就在短句子末尾(或开头)插入若干 <pad>,使它们和最长句子等长。
-
**<pad>**的作用(Padding Token)
占位:不携带实际语义,只是占位符,告诉模型“这里没有有效内容”。
-
用法
-
训练阶段 (Training)
-
通常把多条样本组成一个 mini‑batch,为了并行计算,必须把它们 pad 到相同长度。
-
短序列末尾填
<pad>,并在计算 attention 和 loss 时用 Padding Mask屏蔽掉这些无效位置。
-
-
推理阶段 (Inference)
-
单条序列自回归:如果你逐步(step by step)用 beam search 或 greedy decode,一次只处理一个“历史”序列,根本没必要 pad,因为每次输入长度正好是历史 token 数。
-
Batch 并行推理:如果你想同时对多条输入做并行推理,就要把它们 pad 到同一长度,此时同样需要
<pad>+ Padding Mask,屏蔽无效位置。
-
-
Mask(掩码介绍)
-
Padding Mask(填充掩码)
-
训练/推理都生效:因为无论是在训练还是在推理阶段,你都需要屏蔽序列中真正的
<pad>token,避免模型把注意力分配到这些“无效”位置。 -
在 Encoder Self‑Attention 和 Cross‑Attention(Decoder→Encoder 部分)里,都会用到 Padding Mask。
-
-
Causal Mask / Look‑Ahead Mask(因果/前瞻掩码)
-
仅在并行训练时生效:在训练阶段,为了并行计算整个目标序列,必须用 Causal Mask 把未来位置屏蔽,确保第 t 步只能 attend 到前 t 个 token。
-
推理阶段一般不需要:推理时,每一步只拿到已经生成的历史 token,没有任何“未来” token,自然不存在要屏蔽的位置,因此无需额外应用 Causal Mask。
-
三处 Attention 对比
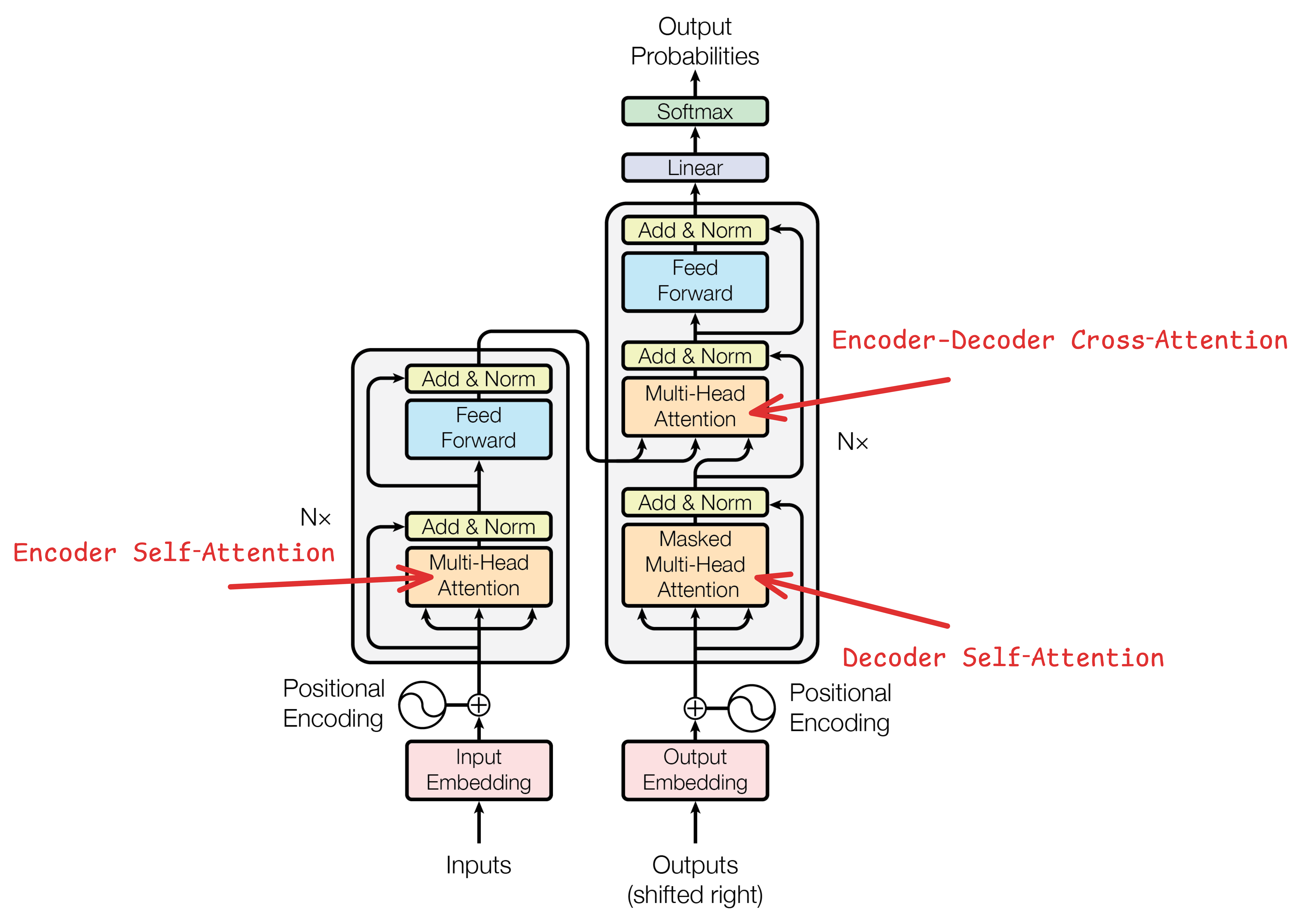
| 特性 | Encoder Self‑Attention | Decoder Self‑Attention | Encoder–Decoder Cross‑Attention |
| Q/K/V 来源 | 同一源序列 | 同一目标序列 | Q 来自 Decoder,K/V 来自 Encoder |
| Mask | Padding Mask | Padding + Look‑Ahead Mask | Padding Mask(源序列) |
| 并行 vs 自回归 | 可全并行 | 训练时可并行,推理时自回归 | 可并行 |
| 作用 | 构建全局编码上下文 | 保证自回归因果约束 | 注入源序列上下文到解码 |
3.3.8 手撸 Attention 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class AttentionLayer(nn.Module):
def __init__(self, input_dim):
super().__init__()
self.query = nn.Linear(input_dim, input_dim)
self.key = nn.Linear(input_dim, input_dim)
self.value = nn.Linear(input_dim, input_dim)
def forward(self, x):
Q = self.query(x) # (batch_size, seq_len, dim)
K = self.key(x) # (batch_size, seq_len, dim)
V = self.value(x) # (batch_size, seq_len, dim)
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(Q.size(-1)))
weights = F.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output
3.4 Multi-Head Attention(MHA)——**多头注意力,**Attention 机制的优化
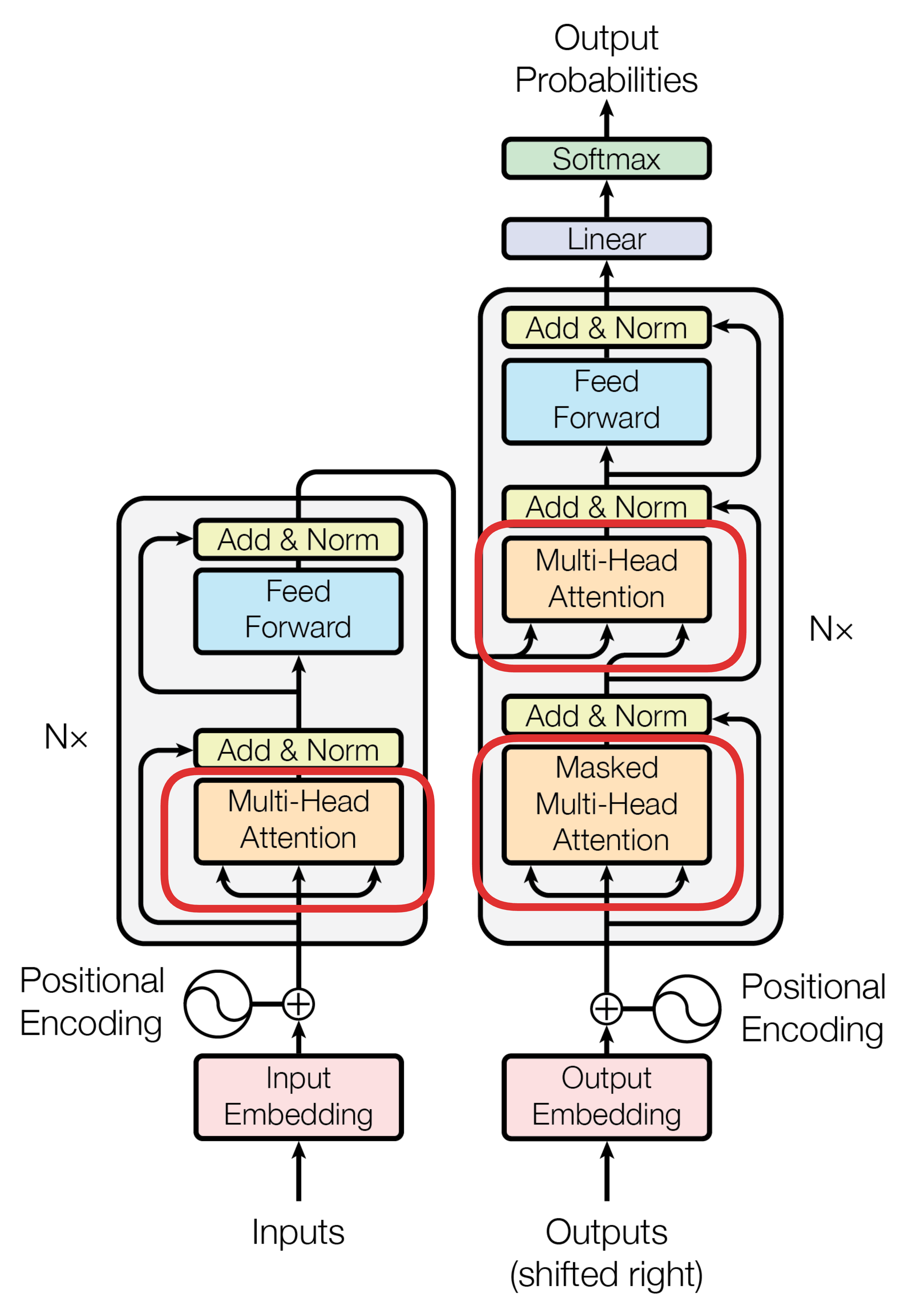
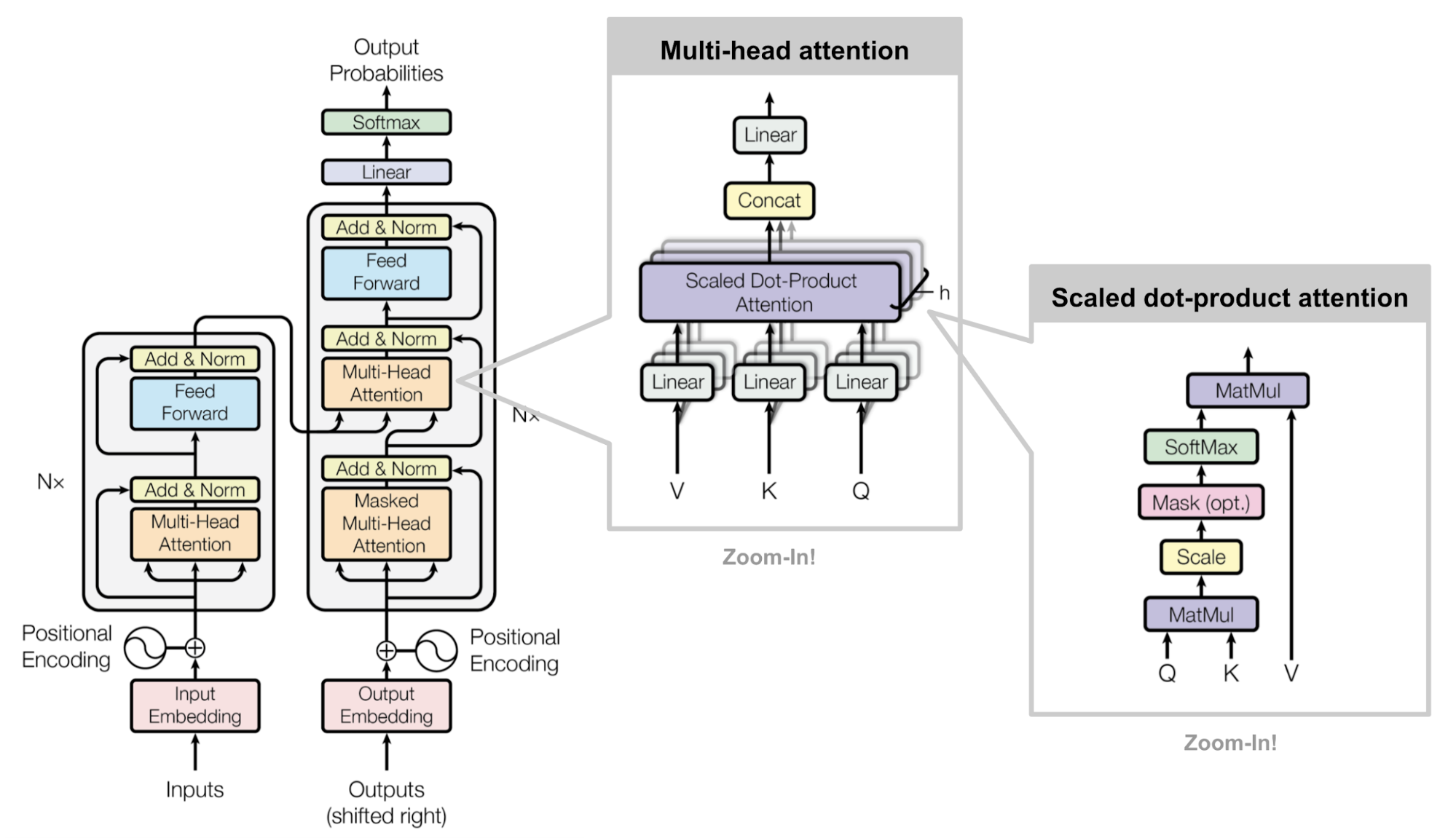
Multi-Head Attention(MHA,多头注意力)是Transformer模型中的核心组成部分,它通过并行计算多个注意力机制(Attention Heads)来捕捉输入数据中丰富的特征和不同的语义关系。
3.4.1 为什么会有 MHA?
Multi-Head Attention(MHA,多头注意力)优化的主要原因在于它能显著提升模型捕捉信息和表征能力的灵活性与效率。
-
**捕捉多样化的特征信息:**单一的注意力头在处理输入数据时,通常只能从一个角度(或者子空间)捕捉关系。而 MHA 通过将输入数据分别映射到多个不同的子空间,每个头能够专注于数据中的不同特征或语义信息。例如,一个注意力头可能专注于捕捉局部依赖关系,而另一个可能更关注全局信息,从而使整个模型能够获得更为丰富和细致的表征。每个独立的注意力头学习到的信息具有互补性。当我们将各个头的输出拼接再经过一次线性变换后,可以获得一个综合多角度信息的结果,这大大增强了模型对输入数据复杂关系的理解能力。
-
**提高模型的表达能力:**如果只采用单个注意力头,那么输出很可能受限于该头所学习到的单一模式,可能忽略其他重要的特征。而 MHA 能够并行处理多个信息流,分散风险,避免单一注意力头可能遇到的信息瓶颈问题,从而有效提高模型整体的表达能力和鲁棒性。
-
**并行计算:**每个注意力头的计算是相对独立的,因此可以并行执行。这种并行性不仅加快了计算速度,也使得模型在处理长序列时更为高效。
3.4.2 MHA的原理
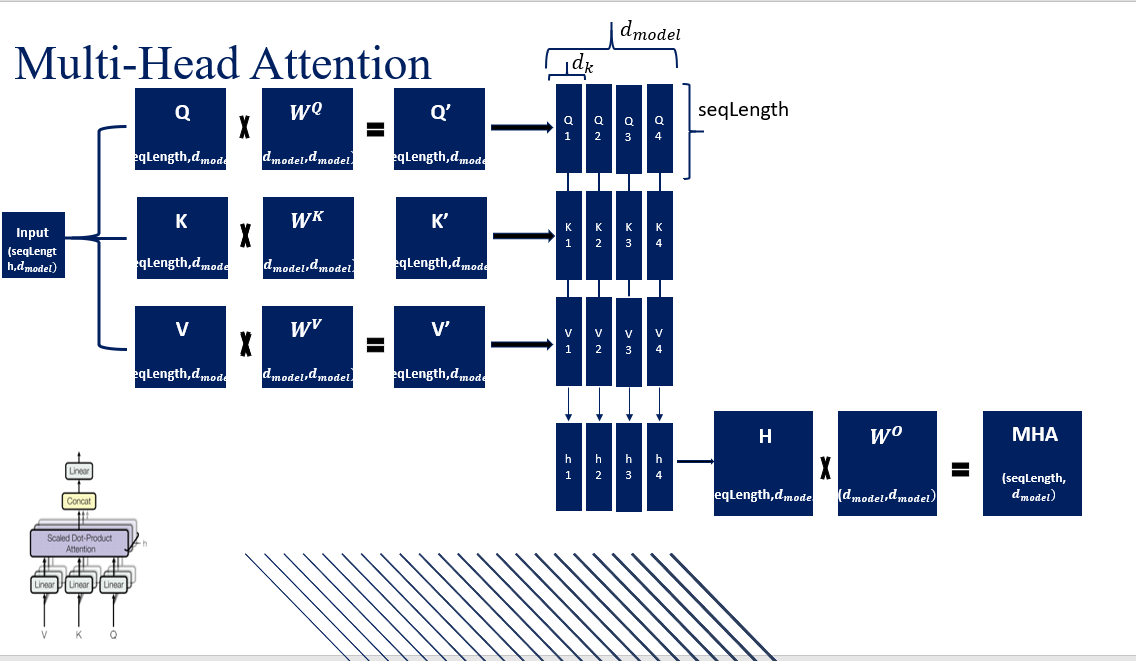
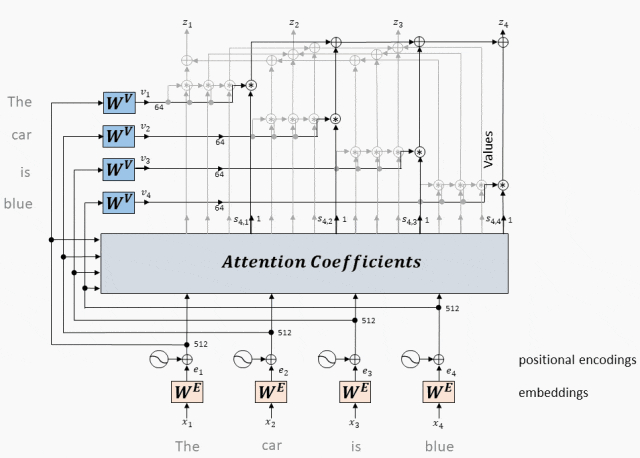
MHA 的核心思想在于并行计算多个注意力头。具体操作如下:
-
**线性变换:**输入序列X形状通常为(\text{seq\_length}, d_{\text{model}}),通过三个不同的线性映射生成 Query、Key 和 Value:Q = XW^Q,\quad K = XW^K,\quad V = XW^V,其中W^Q, W^K, W^V 分别为相应的投影矩阵。
-
**分头操作:**将投影后的Q,K,V按照注意力头数h划分为多个部分。比如说,对于模型维度d_{\text{model}},一般会设置每个头的维度为d_k = \frac{d_{\text{model}}}{h}(竖向切分)因此,每个头都会有形状为 (\text{seq\_length}, d_k) 的Q,K,V。
-
计算缩放点积注意力(Scaled Dot-Product Attention):略
-
**拼接与输出映射:**将所有注意力头的输出在特征维度上拼接起来:\text{Concat}(\text{head}_1, \text{head}_2, \dots, \text{head}_h)最后,再通过一次线性映射(投影矩阵W^O)得到最终的输出:\text{Output} = \text{Concat}(\text{head}_1, \dots, \text{head}_h) \, W^O
3.4.3 W^O矩阵的作用
W^O矩阵是一个需要训练的矩阵。作为一个可训练的参数矩阵,能够在整个训练过程中不断优化,自动调整如何组合各个头的信息,使得整体表示能够更好地满足下游任务的需求。换句话说,即使维度未发生变化,该矩阵仍然提供了一种“调节器”的作用,可以增强模型的表达能力。每个注意力头关注于输入的不同子空间或特征维度,拼接后的结果只是将这些独立头的输出简单地连接起来。通过W^O矩阵,模型可以对这些信息进行线性组合,从而学习如何在各个头之间重新分配权重、融合多种视角的信息,使得最终的表示更加丰富和有效。
3.5 Positional Encoding——位置编码,让 Attention 更准确的理解 token之间的关系
https://kexue.fm/archives/9431
https://kexue.fm/archives/9444
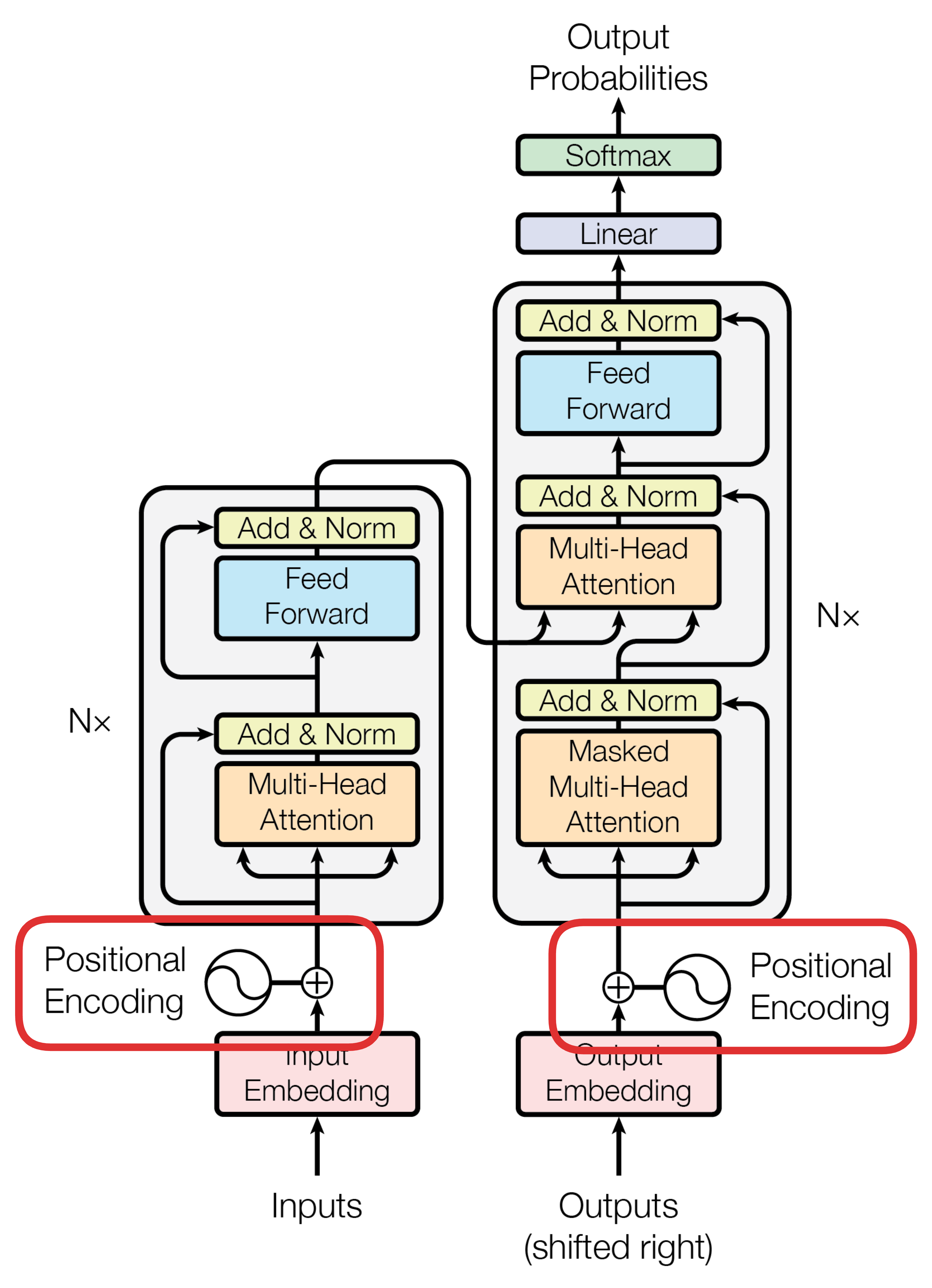
Transformer 对 Input/ output embedding 增加了位置编码的操作,这是为什么呢?
3.5.1 Attention 的不足——无法捕捉 Token 的顺序关系
双向Attention具有置换不变性,即 Attention 的结果与自然语言的Token 顺序无关,这与人类的语言使用习惯相违背
单向 Attention本身不具备置换不变性,主要是通过 hidden state 向量的方差来表达顺序关系的。“能凑合用,但不够好”
所有,我们需要一些机制来让 Attention 更准确的理解 token之间的关系
既然如此位置编码的设计需要满足哪些目标呢?
3.5.2 位置编码的设计目标
-
捕捉位置信息:使模型能够感知序列中各 token 的顺序和相对位置,从而正确理解自然语言中的语法和语义结构。
-
唯一性和区分度:为每个位置生成一个独特的表示,确保不同位置的 token 能被区分开,即使它们的内容相同。
-
长度外推性:设计上能够适应比训练时更长的序列,保证在推理时也能生成合理的位置信息。
-
数学友好性:利用正弦、余弦等连续、周期性的函数,使得位置信息具有平滑性和相对关系,便于模型通过简单的线性组合捕捉相对位置信息。
-
高效计算:保持实现简单且计算开销低,适合并行化计算,满足大规模模型的需求。
总的来说,位置编码旨在为 Transformer 模型提供丰富且唯一的位置信息,使得模型能够利用 token 的顺序和相对位置,进而提升对序列数据的理解和处理能力。
按照这些指标,我们来看一下位置编码的实现方式
3.5.3 Absolute Position Encoding——绝对位置编码
绝对位置编码的主要设计思路是为序列中每个位置生成一个唯一的编码,代表该位置在整个序列中的固定“绝对”位置。
绝对位置编码有多种思路实现
Learned Positional Encoding——可学习的绝对位置编码
很显然,绝对位置编码的一个最朴素方案是不特意去设计什么,而是直接将位置编码当作可训练参数,比如最大长度为512,编码维度为768,那么就初始化一个 512×768 的矩阵作为位置向量,让它随着训练过程更新。BERT、GPT等模型所用的就是这种位置编码,事实上它还可以追溯得更早,比如2017年Facebook的 Convolutional Sequence to Sequence Learning 就已经用到了它。此外这种编码可以在每一层中以不同方式学习 (https://arxiv.org/abs/1808.04444)。
对于这种训练式的绝对位置编码,一般的认为它的缺点是没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。
Sinusoidal Positional Encoding——正弦位置编码,Transformer 的标准实现
如 Transformer 原始论文中提出的正弦和余弦函数生成的编码,公式为
PE_{(pos,2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)
PE_{(pos,2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)
这种方式不需要训练参数,具备很好的长度外推性。
其中PE_{(pos,2i)}PE_{(pos,2i+1)} 分别是位置pos的 token embedding 的第2i,2i+1个分量,d_{\text{model}}是向量维度
举个例子:
模型维度d_{\text{model}}=4
我们只计算两个位置pos=1和pos=2
按照公式计算四个维度 0,1,2,3,即取i=0和i=1
- 确定每个维度的缩放因子
对于i=0(对应维度0和1):指数\frac{2i}{d_{\text{model}}} = \frac{0}{4}=0,所以10000^{0}=1。
对于i=1(对应维度2和3):指数\frac{2i}{d_{\text{model}}} = \frac{2}{4}=0.5,所以10000^{0.5} = \sqrt{10000} = 100。
- 计算位置编码
- 对于位置 pos=1:
维度0(偶数):PE(1,0)= \sin\Big(\frac{1}{1}\Big)= \sin(1) \approx 0.84.
维度1(奇数):PE(1,1)= \cos\Big(\frac{1}{1}\Big)= \cos(1) \approx 0.54.
维度2(偶数):PE(1,2)= \sin\Big(\frac{1}{100}\Big)= \sin(0.01) \approx 0.01.
维度3(奇数):PE(1,3)= \cos\Big(\frac{1}{100}\Big)= \cos(0.01) \approx 0.99995.
所以位置1的编码约为[0.84,\ 0.54,\ 0.01,\ 0.99995]。
- 对于位置 pos=2:
维度0:PE(2,0)= \sin(2) \approx 0.91.
维度1:PE(2,1)= \cos(2) \approx -0.42.
维度2:PE(2,2)= \sin\Big(\frac{2}{100}\Big)= \sin(0.02) \approx 0.02.
维度3:PE(2,3)= \cos\Big(\frac{2}{100}\Big)= \cos(0.02) \approx 0.9998.
所以位置2的编码约为[0.91,\ -0.42,\ 0.02,\ 0.9998]。
如下图给出了一个带有L=32(Token 的数量是 32) 和d_{\text{model}}=128 的正弦位置编码。数值介于 -1(黑色)和 1(白色)之间,而 0 为灰色。
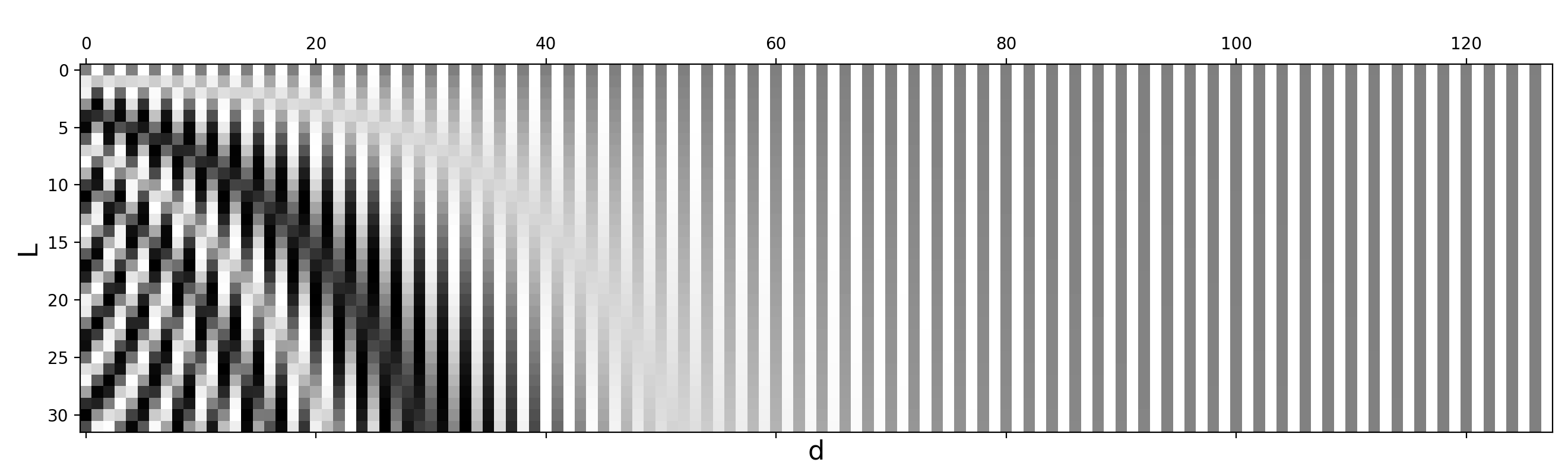
很明显,正弦位置编码的特点是有显式的生成规律,因此可以期望于它有一定的外推性。
绝对位置编码如何与 Token embedding 融合?
一般是直接使用每个元素相加的方式,比如 Token embedding [1,2,3],位置编码[0.1,0.2,0.3], 那么最后的结果就是[1.1,1.2,1.3]
绝对位置编码如何选择?
Transformer 论文里比较了 Learned Positional Encoding 和 Sinusoidal Positional Encoding,发现这两种方法产生的结果几乎完全相同。选择正弦位置编码是因为它可能使模型能够外推到比训练时遇到的序列更长的长度。
3.5.4 Relative Position Encoding——相对位置编码
相对位置编码起源于Google的论文《Self-Attention with Relative Position Representations》,相对位置并没有完整建模每个输入的位置信息,而是在算Attention的时候考虑当前位置与被Attention的位置的相对距离,由于自然语言一般更依赖于相对位置,所以相对位置编码通常也有着优秀的表现。对于相对位置编码来说,它的灵活性更大,更加体现出了研究人员的“天马行空”。
在计算注意力分数时,通常是计算 query 与 key 的点积。相对位置编码的方式会根据两个 token 的相对位置d = i - j添加一个偏置项 b(d)到点积上:\text{Attention Score}_{i,j} = Q_i \cdot K_j^T + b(i,j)
其中b(i,j)就是由相对位置信息(比如距离d)映射得到的偏置。这一步骤将 token 的语义信息和相对位置信息结合在了一起,从而在 softmax 前影响注意力权重的分布。
相对位置编码主要有如下优势:
-
捕捉相对关系:绝对位置编码给出的是每个 token 的“绝对”位置,而相对位置编码直接反映 token 之间的距离。
-
提高泛化能力:由于只关注 token 之间的相对距离,相对位置编码在面对超出训练长度的序列时具有更好的外推能力,能够在不同长度的输入上保持一致的表现。
-
灵活性:相对位置编码允许模型更灵活地捕捉局部结构,比如语言中的短语和依赖关系,而不依赖于固定的绝对位置表示。
3.5.5 融合式位置编码
既然 绝对位置编码与 相对位置编码各有优点,那能不能将两种的优点都结合起来呢?这就是我们将要介绍的 RoPE,也是目前 LLM 的主流位置编码。
Rotary Position Embedding(RoPE)——旋转位置编码
https://arxiv.org/abs/2104.09864
Transformer升级之路:2、博采众长的旋转式位置编码
Transformer升级之路:10、RoPE是一种β进制编码
RoPE 是 苏剑林提出的一种 旋转位置编码,也是目前 LLM 的主流编码,RoPE 的目标是让 Transformer 模型在计算 Query 和 Key 的内积时,自然地包含相对位置信息,而无需引入额外的相对位置偏置。它通过对 Query 和 Key 向量进行位置相关的旋转操作,使得不同位置的向量在进行点积时,其结果能够反映出 token 之间的相对距离。
传统的绝对位置编码(如正弦/余弦编码)是将位置信息加到 token embedding 上,而 RoPE 则直接修改 Query 和 Key 的计算结果,利用欧几里得空间中的旋转操作,将相对位置嵌入表述为仅通过将特征矩阵按与其位置索引成比例的角度旋转的方式,使得内积操作中自动包含位置信息(旋转操作引入绝对位置,向量本身的距离引入相对位置)。
RoPE 的原理:
给定向量z,如果我们想将其逆时针旋转θ,可以将其与旋转矩阵相乘得到Rz,其中旋转矩阵R定义为:
R = \begin{bmatrix}\cos\theta & -\sin\theta \\\sin\theta & \cos\theta\end{bmatrix}
当推广到高维空间时,RoPE 将d维空间划分为d/2个子空间(一般来说,模型的维度都是偶数),并为位置i的 token 构造了一个大小为 d×d的旋转矩阵R,其中\Theta = {\theta_i = 10000^{-2(i−1)/d}, i \in [1, 2, …, d/2]}:
R^d_{\Theta, i} = \begin{bmatrix}\cos i\theta_1 & -\sin i\theta_1 & 0 & 0 & \dots & 0 & 0 \\\sin i\theta_1 & \cos i\theta_1 & 0 & 0 & \dots & 0 & 0 \\0 & 0 & \cos i\theta_2 & -\sin i\theta_2 & \dots & 0 & 0 \\0 & 0 & \sin i\theta_2 & \cos i\theta_2 & \dots & 0 & 0 \\\vdots & \vdots & \vdots & \vdots & \ddots &\vdots & \vdots \\0 & 0 & 0 & 0 & \dots & \cos i\theta_{d/2} & -\sin i\theta_{d/2} \\0 & 0 & 0 & 0 & \dots & \sin i\theta_{d/2} & \cos i\theta_{d/2} \\\end{bmatrix}
然后Key和Query矩阵通过与这个旋转矩阵相乘来包含位置信息:
\begin{aligned}& \mathbf{q}_i^\top \mathbf{k}_j = (R^d_{\Theta, i} \mathbf{W}^q\mathbf{x}_i)^\top (R^d_{\Theta, j} \mathbf{W}^k\mathbf{x}_j) =\mathbf{x}_i^\top\mathbf{W}^q R^d_{\Theta, j-i}\mathbf{W}^k\mathbf{x}_j \\& \text{ where } R^d_{\Theta, j-i} = (R^d_{\Theta, i})^\top R^d_{\Theta, j}\end{aligned}
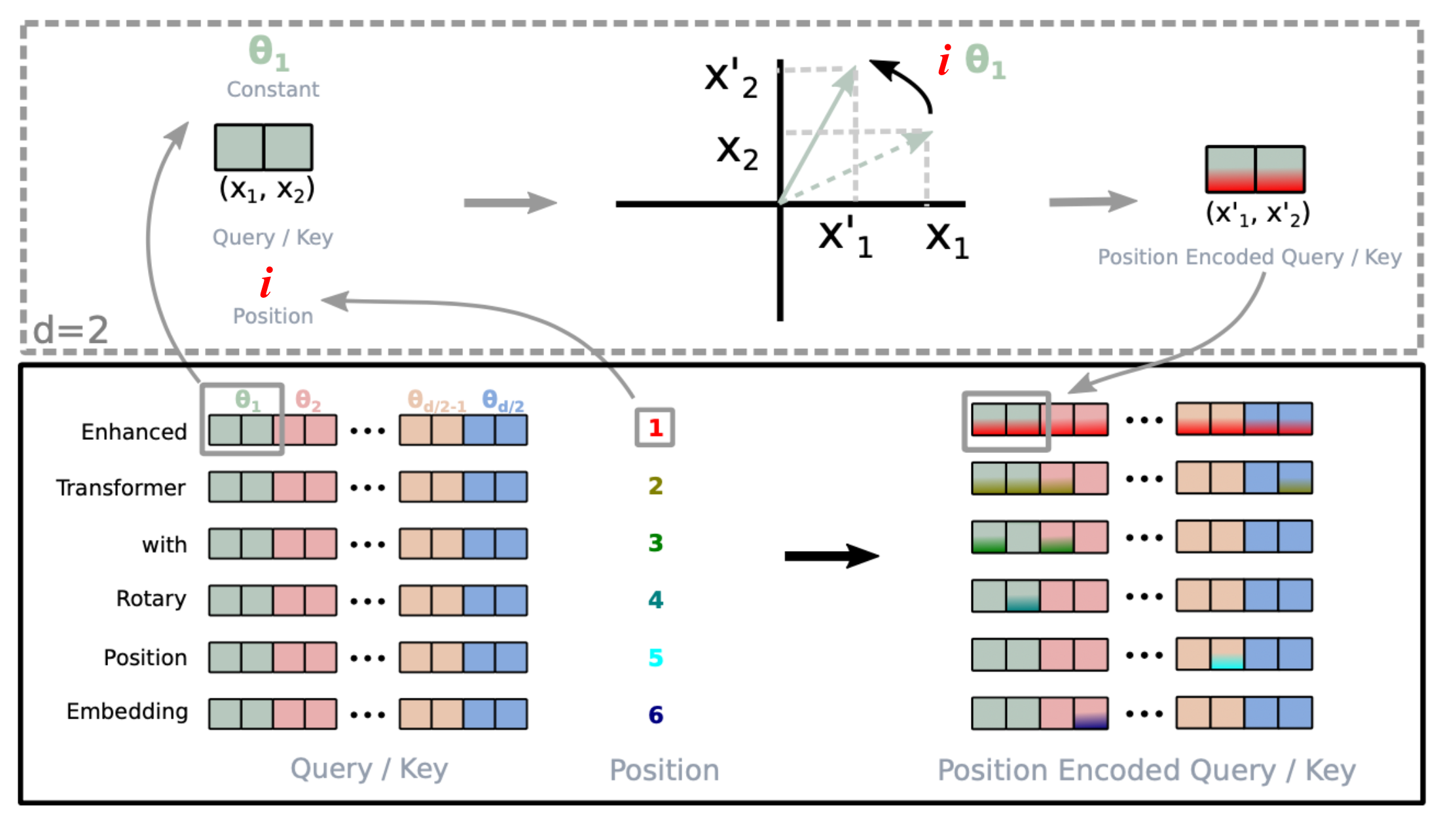
如上,通过将 Query 和 Key 向量在每个维度对上进行与位置相关的旋转,将相对位置信息直接融入到注意力计算中。这样,模型在计算内积时不仅考虑了内容相似性,还自动捕捉了 token 之间的相对距离信息。详细来说,它对每个 token 的向量按照一个与位置相关的角度进行旋转,而在计算两个 token 内积时,这个旋转差就反映了它们之间的位置差距,从而提高了模型对序列中相对顺序和距离的感知能力。
现在,我们补足了 Attention 的短板,现在 Attention 变成了完全体,既可以理解 Token 本身,也可以理解 Token 的顺序了!
但是 Attention 终究只是让我们有了关注重点的能力,它本质上是一个线性操作(例如,通过点积计算相似度和加权求和)。如果仅依靠 attention 层,模型很难对每个 token 的特征做进一步的非线性变换和深层次的信息抽象。
3.6 Position-wise Feed-Forward Networks**(**Position-wise FFN)——逐位置前馈网络
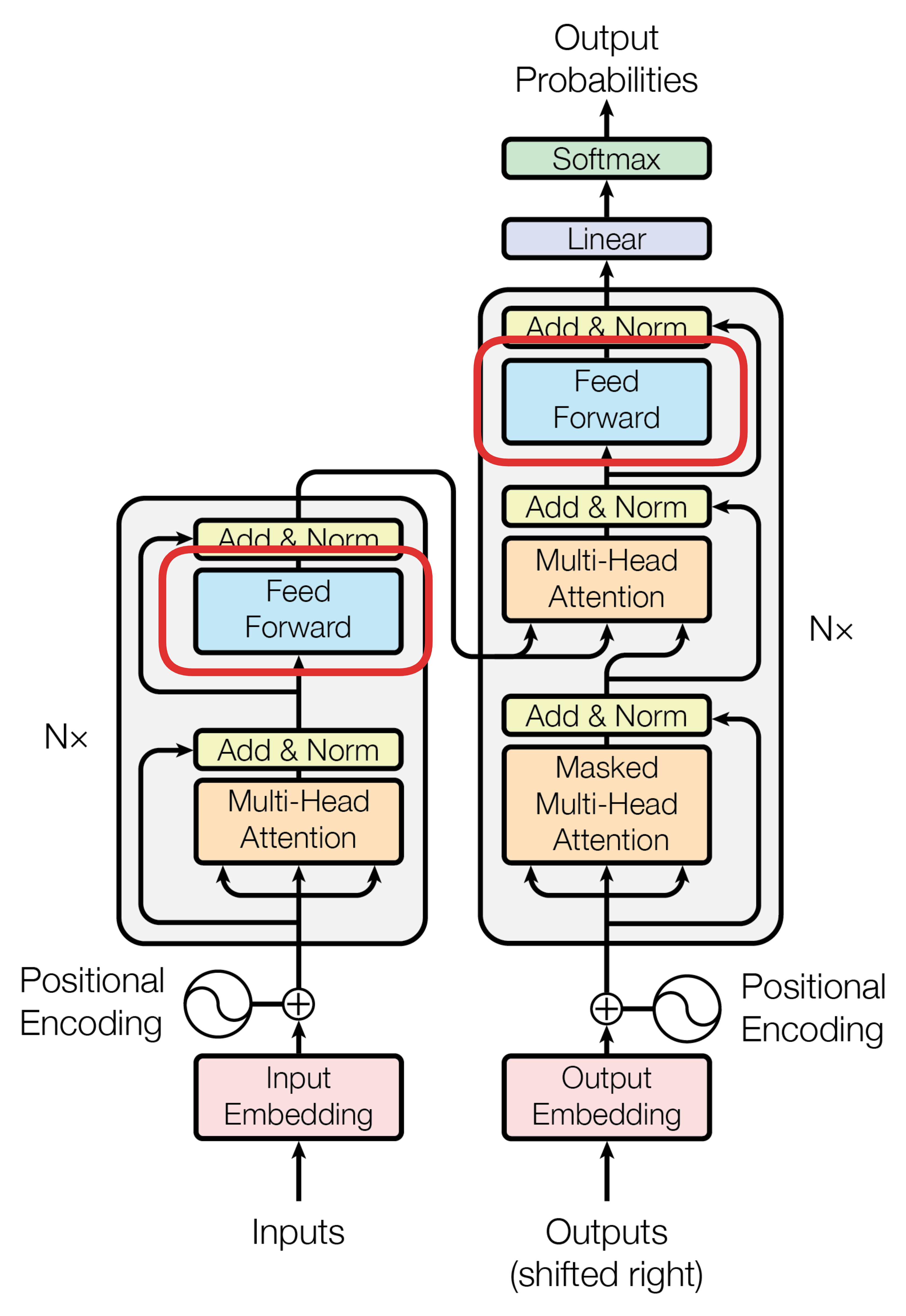
Position-wise Feed-Forward Networks(逐位置前馈网络)是 Transformer 架构中非常核心的组成部分。
Position-wise 的意思是对于输入序列中每个位置(即每个 token)的表示,前馈网络都会采用完全相同的参数独立地进行非线性变换。也就是说,尽管输入序列可能有不同长度,但 FFN 的计算是逐位置、相互独立的,每个位置的变换都使用同一个前馈网络。
Transformer 中的自注意力层负责捕捉序列中各个 token 之间的全局依赖关系,而 FFN 则负责对每个 token 的局部表示进行进一步的非线性转换和特征提取。二者结合,使得模型既能捕捉全局关系,又能对局部特征进行深度处理。
3.6.1 FFN 的核心组成
-
第一层全连接层:线性变换升维操作,将每个 token 的表示从d_{\text{model}}映射到d_{\text{ff}}。
-
非线性激活:通过 ReLU 或 GELU 等激活函数引入非线性。
-
第二层全连接层:线性变换降维操作,将高维特征映射回原始维度。
详细说明:
-
输入:每个 token 在经过 self-attention 模块后,会得到一个向量 x,维度为 d_{\text{model}}(例如 512、768 等)。
-
第一层线性变换(升维):将输入的d_{\text{model}} 维向量映射到更高维的空间,通常称为扩展或升维。
使用一个权重矩阵W_1和偏置b_1,将输入x变换为:x' = xW_1 + b_1其中W_1的形状通常是 d_{\text{model}} \times d_{\text{ff}},而d_{\text{ff}}(例如 2048 或 3072)远大于d_{\text{model}}。
升维后,可以在更大的特征空间中捕获和表达更多的细节信息,使得后续的非线性激活能够发挥更大的作用。
-
激活函数:在第一层线性变换后,加入非线性激活函数(常用 ReLU 或 GELU),将线性输出x'转化为非线性特征:x'' = \text{Activation}(x')引入非线性因素,使网络能够学习复杂的特征映射,而不仅仅局限于线性组合。
-
第二层线性变换(降维):将激活函数输出的高维表示重新映射回原始的d_{\text{model}}维度,保证整个 Transformer 层的维度一致性。
使用另一个权重矩阵W_2和偏置b_2,具体公式为:\text{FFN}(x) = x''' = x''W_2 + b_2其中W_2的形状为d_{\text{ff}} \times d_{\text{model}}。
- 将以上各部分串联起来,Position-wise FFN 的整体计算公式为:\text{FFN}(x) = W_2\bigl(\text{Activation}(xW_1 + b_1)\bigr) + b_2
这种结构设计使得 Transformer 在处理复杂任务时既能捕捉全局依赖,又能对局部特征进行深入变换,从而提升整体模型的表现力。
通过 FFN之后,也就经过了 Encoder 和 Decoder 的全流程,我们获得了最终输出的向量矩阵,那我们怎么把向量转成文字呢?
3.7 Regularization——正则化,提升模型泛化能力
在 Transformer 中,Regularization(正则化)的主要目的是防止模型过拟合,提升模型的泛化能力,并确保训练过程更加稳定。Transformer 模型参数量巨大,如果不加以正则化,模型很容易在训练数据上学得过于细致,而对新数据的预测效果较差
3.7.1 Dropout——缓解过拟合
Dropout: a simple way to prevent neural networks from overfitting.Journal of Machine Learning Research
https://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf
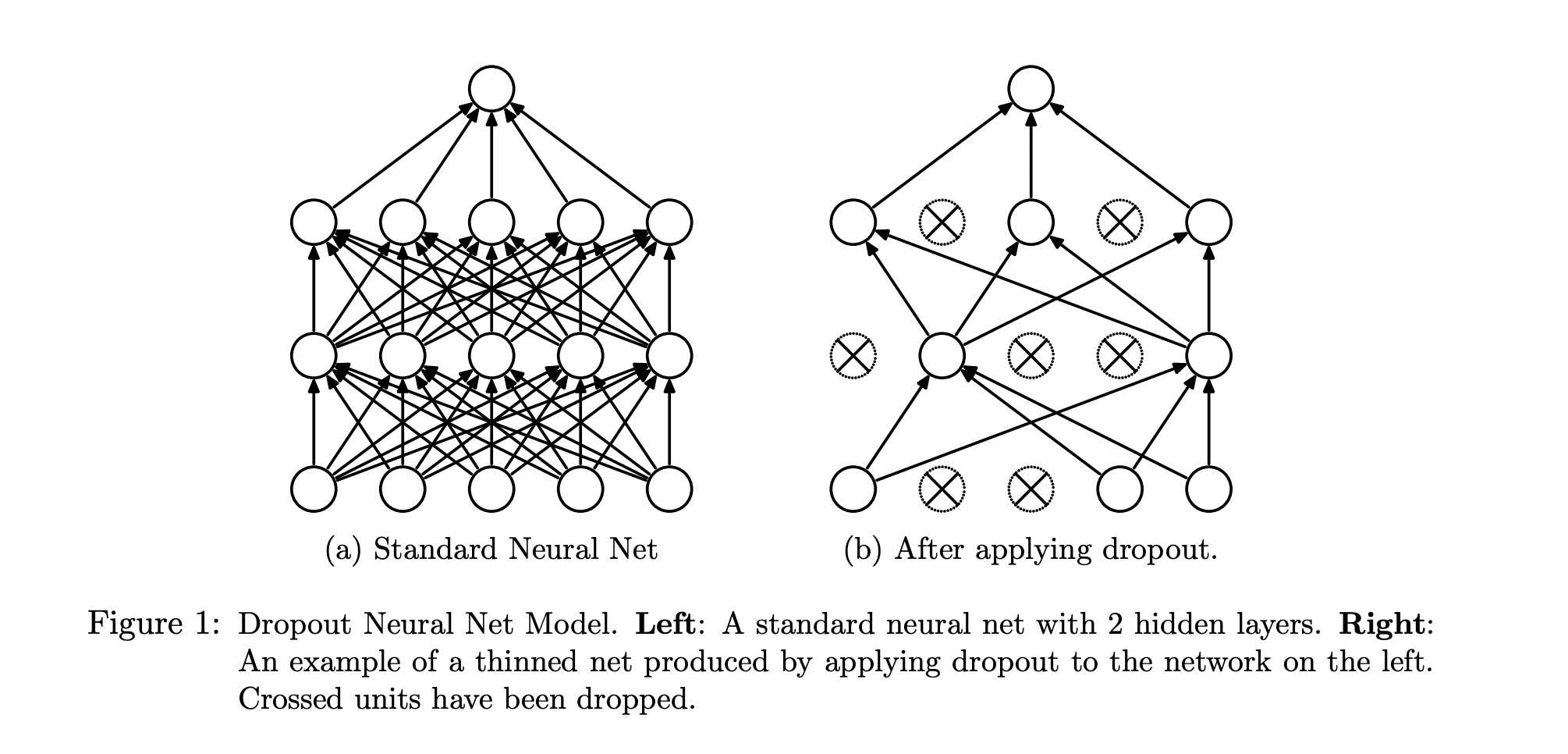
Dropout 是一种在训练神经网络时经常使用的正则化技术,是在训练过程中对网络中某一层的输出 activations 做随机屏蔽,从而减少网络对特定神经元之间相互依赖的情况,这样做能够在一定程度上缓解过拟合问题。在原始论文《Attention is All You Need》中,作者选择了较小的 Dropout 比例( 0.1),这种设计既能引入有效的随机性,又不至于严重破坏信息流。
使用的位置
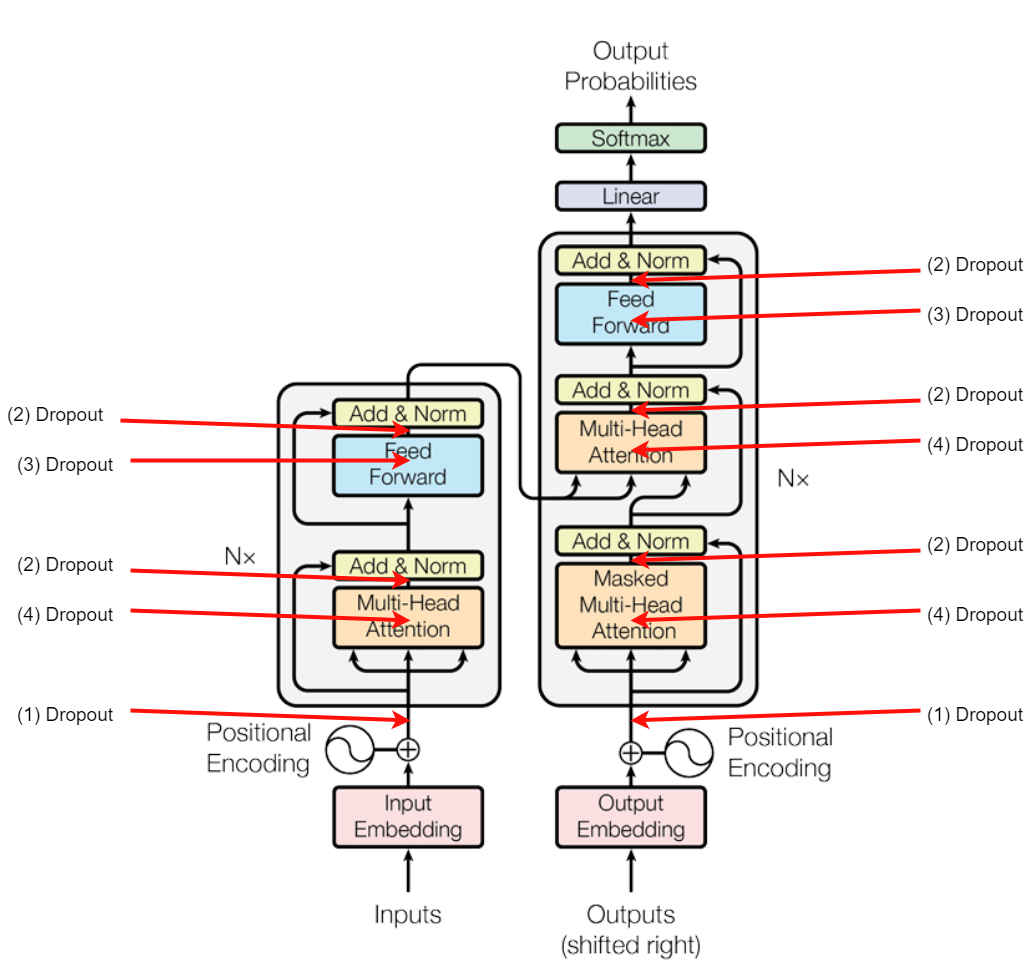
-
**Self-Attention:**Dropout在 Scaled Dot-Product Attention 中,首先会根据 Queries 和 Keys 计算得到注意力分数,并经过 softmax 得到注意力权重。在这之后,会对注意力权重施加 Dropout,这意味着在计算加权和时,会有一部分权重被随机置零,从而使得模型在训练过程中不会过分依赖某些特定位置的信息。
-
**Feed-Forward Network:**Transformer 每一层的结构中包含一个位置上独立的全连接前馈网络。通常在前馈网络中,经过激活函数(例如 ReLU)后,会对中间结果应用 Dropout,然后再经过第二个全连接层。这样可以防止前馈层过拟合,并促使网络学到更加分散的特征表示。
-
**Residual Connection 前:**在 Encoder 和 Decoder 的每个子层(例如 Self-Attention 或前馈网络)之后,常常会在将子层的输出与输入做 Residual 连接之前,对子层输出施加 Dropout。这样在残差加法时就引入了一定的随机性,降低了局部特征对后续层的过分影响,同时有助于平滑训练过程。
-
Embedding:在 Transformer 模型的最前端,会将 token 和位置编码相加形成最终的输入表示。通常在这个阶段也会对输入 Embedding 施加 Dropout,使得模型不会过于依赖于输入的某一部分信息。
主要原理
在每次前向传播时,Dropout 会以一定概率(例如常用的 0.5 或 0.1 等)将该层中部分神经元的输出置为 0,这意味着这些神经元在当前训练步中不参与计算。这样做的目的是迫使网络不能依赖于某个特定的神经元,从而提升模型的鲁棒性并降低过拟合风险。Dropout 主要应用于神经元的输出,也就是激活值。通过随机屏蔽激活值,模型在每次前向传播中都会使用不同的子网络组合来进行预测。在标准的 Dropout 中,权重矩阵保持不变,只有输出的 activations 被随机丢弃。也就是说,网络的参数在训练过程中不会直接被“屏蔽”。
为什么可以缓解过拟合?
-
**减少神经元之间的 co-adaptation(共适应):**在没有 Dropout 的情况下,神经元在训练过程中容易形成高度依赖的关系,某些神经元会共同适应特定的训练样本,从而使网络容易对训练数据产生过强的记忆。Dropout 强制网络在每次训练时只能依靠部分神经元来传递信息,这就迫使神经元独立地学习更加鲁棒的特征表示,降低了过拟合风险。
-
**模型集成的效果:**可以把 Dropout 理解为对多个子网络进行集成的近似——每次训练时舍弃一部分神经元,相当于在训练不同的“子网络”。在测试时使用全模型(并对激活值缩放),相当于将这些子网络的输出进行加权平均。集成方法通常能提高模型的泛化能力,因为不同子模型的误差在集成中会相互抵消。
-
**降低模型复杂度:**随机丢弃部分神经元可以看作降低了模型的复杂度,使得模型不容易过度拟合训练数据的噪声。这样模型被迫学习更简洁、更稳定的特征表示,从而在面对未见数据时能有更好的泛化性能。
-
**避免局部最优解的依赖:**Dropout 促使模型不同部分学会在信息缺失的情况下仍能有效工作,这样可以使网络在优化过程中更难陷入只依赖局部特定特征的状态,从而提高整体鲁棒性。
3.7.2 Label Smoothing——**标签平滑,**提高泛化能力
Label Smoothing(标签平滑)常用于分类任务的模型训练中,它主要通过对真实标签分布进行“软化”,使得模型在训练时不会变得过于自信,从而提高模型的泛化能力。
Transformer 的标签
标签是在模型训练时用于计算loss的关键输入,指导模型调整参数,以提高预测准确度和泛化能力。
模型经过 softmax 后会输出一个概率分布,这时标签作为“真实”目标,用于与模型预测的分布计算交叉熵损失(Cross Entropy Loss)。这个损失函数衡量了预测分布与目标分布之间的差异。通过交叉熵损失计算出的误差会反向传播到整个网络,以更新模型参数,从而使得下一次预测时模型输出的概率分布更接近真实标签分布。
标签平滑原理
在传统的分类任务中,通常使用 one-hot 编码作为目标标签。例如,对于一个包含K个类别的分类任务,如果样本的真实类别为y,则目标分布 q 通常表示为:
q(i)=\begin{cases}1, & \text{if } i=y \\0, & \text{otherwise}\end{cases}
这种硬性分布会使模型在训练时倾向于输出一个过于尖锐(peaked)的概率分布,即模型很容易变得过于自信,认为某个类别的概率几乎为 1,而其他类别为 0。
Label Smoothing 的思想就是对这种 one-hot 编码进行“平滑”处理:
在平滑后的标签中,真实类别的概率不再是 1,而是降低到1-\varepsilon(其中\varepsilon 为平滑参数,通常取小值,如 0.1),而将剩下的 \varepsilon 分配给其他类别,通常每个其他类别均分到 \frac{\varepsilon}{K-1}。
数学上,经过 Label Smoothing 后,目标分布 q_{\text{smooth}}(i) 可以表示为:
q_{\text{smooth}}(i)=\begin{cases}1-\varepsilon, & \text{if } i=y \\\frac{\varepsilon}{K-1}, & \text{otherwise}\end{cases}
这种处理使得目标分布变得“平滑”,即不会要求模型对真实类别输出过高的置信度,降低了对数似然损失的过大梯度,从而对模型训练起到了正则化作用。
为什么可以缓解过拟合?
由于对训练目标进行了平滑,不再要求模型将某个类别的概率逼近 1,这有效减少了模型在训练时因过度自信而学习到训练数据噪声的可能性,从而降低了过拟合风险。
为什么可以泛化?
平滑标签可以让模型学会对输入数据保留一定的不确定性,这往往能够在测试时使模型表现更稳健,对未见样本的预测更具有鲁棒性。
3.7.3 Residual Network(ResNet)——残差链接,解决因为大模型层数过深导致的效果退化问题
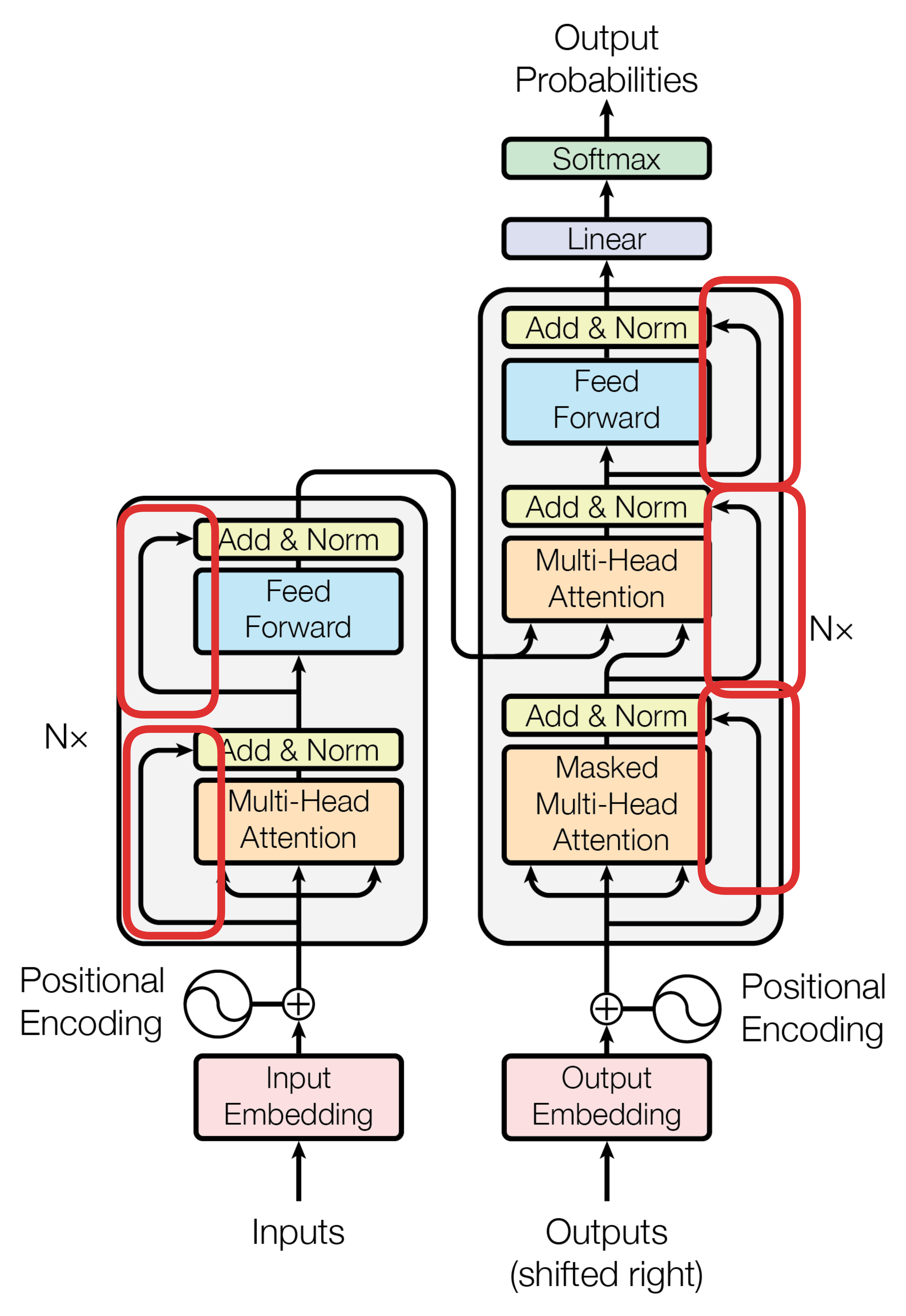
残差链接是一种神经网络架构设计技巧,用于缓解深层神经网络训练过程中的梯度消失和网络退化问题。
原理
在传统的深层网络中,随着层数增多,梯度在反向传播过程中会逐渐消失或爆炸,导致网络难以优化。残差链接通过让某一层的输出不直接经过多个非线性变换,而是将输入直接添加到输出上,即学习残差函数(Residual Function),进而转化为:\mathbf{y} = \mathcal{F}(\mathbf{x}) + \mathbf{x}
其中,\mathbf{x} 是输入,\mathcal{F}(\cdot)表示这一层的非线性变换(如卷积、全连接层、注意力机制等),而\mathbf{y}则为输出。这种设计使得如果网络学习不到有效的映射,至少可以通过残差连接直接传递\mathbf{x}给后续层,从而避免因层数过深导致性能下降的问题。
使用残差链接的原因
由于 Transformer 的层数通常较多(例如许多模型堆叠数十层甚至上百层)深层的网络在训练过程中容易遭遇到如下问题:
-
梯度消失和梯度爆炸问题。残差链接可以有效地保证梯度能够直接沿着捷径回传,稳定训练过程。
-
增量爆炸(在层数变多时,参数的微小变化就会导致损失函数的大变化)。残差可以同时稳定前向传播和反向传播并解决增量爆炸,从而使得深层模型更容易训练。
3.8 Normalization——归一化
每层神经网络的输出往往会随着训练频繁变化,向下一层输入时,往往需要额外实行这些变化而导致不必要的偏离,导致如梯度消失、学习率低下等问题,这该怎么解决呢?我们一般会引入归一化(Normalization) 层,主要是为了提升训练的稳定性与收敛速度。
3.8.1 归一化的目标
解决 Internal Covariate Shift
-
问题描述:在多层网络中,每层输入分布会随着前面层权重更新而频繁变化,这种现象称为 Internal Covariate Shift。
-
危害:
-
后续层需要不断适应新的输入分布,导致学习效率低下;
-
必须使用更小的学习率(learning rate)才能避免发散。
-
-
归一化作用:
-
将每层输入(或激活)统一映射到相对稳定的分布(如均值为 0、方差为 1),减少分布漂移;
-
这样后续层只需关注真正的语义特征更新,而不必“重学”输入统计量。
-
缓解梯度消失与梯度爆炸(Gradient Vanishing/Exploding)
-
梯度消失/爆炸:
- 当网络很深时,误差反向传播时梯度可能指数级衰减或膨胀,导致参数更新困难。
-
归一化优势:
-
保持每层输入的数值尺度在合理区间,避免输入过大或过小;
-
使得激活函数(如
ReLU、SiLU、tanh)工作在更“线性”或“敏感”区间,确保梯度信号能顺利传递。
-
允许使用更大 Learning Rate 与更快收敛
-
如果没有归一化,使用过大的 learning rate 会导致训练不稳定甚至发散;
-
有了归一化后,输入分布被固定,模型对 learning rate 不那么敏感,可以安全地升高学习率,从而加速收敛,节省训练时间。
3.8.2 常见的归一化层及对比
| 归一化方式 | 维度 | 优点 | 典型应用 |
| BatchNorm | 对每个 channel 在 batch 维度上做归一化 | 提供随机正则化,显著加速 CNN 收敛 | 图像模型(ResNet、CNN) |
| LayerNorm | 对最后一维特征做归一化 | 对 batch 大小不敏感,适合 RNN/Transformer | Transformer、RNN |
| GroupNorm | 将 channels 分组后做归一化 | 不依赖 batch size,适合小 batch 或检测任务 | Detection、Segmentation |
| RMSNorm | 对最后一维做 RMS(均方根)归一化 | 计算最轻量,节省一次均值计算 | 大规模 LLM(LLaMA、GPT) |
3.8.3 Layer Normalization(层归一化)的具体实现
Layer Normalization(层归一化,LayerNorm)是将每个样本的某一指定维度(通常是最后一维特征)做归一化,保证该维度上输出的均值为 0、方差为 1,并通过可学习的缩放(gamma)和偏移(beta)来恢复表达能力
原理解析
假设一个元素向量
\mathbf{x} = [x_1, x_2, \dots, x_n]
其中 n是归一化维度大小(normalized_shape)。
-
计算均值(mean)\mu = \frac{1}{n}\sum_{i=1}^n x_i
-
计算方差(variance)\sigma^2 = \frac{1}{n}\sum_{i=1}^n (x_i - \mu)^2
-
归一化\hat x_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}}其中 \epsilon(\epsilon) 是一个小常数(如 e^{-5}),用于防止除零。
-
缩放和偏移y_i = \gamma_i \hat x_i + \beta_i
性能分析
-
计算复杂度:
-
需要两次遍历(一次计算
mean,一次计算var),分别包含加法与乘方操作。 -
对比 RMSNorm(只需一次遍历 + 开根号),LayerNorm 稍慢但更“完整”地消除了偏移和尺度。
-
-
数值稳定性:
-
中心化(
x - mean)加上方差归一能有效抑制输入偏移,对深层网络和小 Batch 情形更稳定。 -
eps大小需适当(推荐1e-5至1e-6),否则易受极端值影响。
-
3.8.4 RMSNorm(Root Mean Square Layer Normalization)
RMSNorm(Root Mean Square Layer Normalization) 是一种轻量化的层归一化方法,用于 Transformer、大型语言模型等场景,核心思想是只用均方根(RMS)而不做去中心化(zero‑mean)处理,从而减少一次张量遍历和参数量。
为什么要用 RMSNorm?
-
LayerNorm 的开销:经典的 LayerNorm 要计算均值(mean)和方差(variance),两次遍历张量,并且带有可学习的 scale(γ)和 bias(β)两组参数。
-
大模型瓶颈:在上百亿乃至千亿参数的模型里,这些开销显著影响显存与吞吐。
-
RMSNorm 目标:通过仅做 RMS 归一化,省略 zero‑mean 和 bias,减少计算与内存成本,同时保持训练稳定。
原理解析
给定一个向量 \mathbf{x}=[x_1, x_2, …, x_n]:
- 计算 RMS
\mathrm{RMS}(\mathbf{x})= \sqrt{\frac{1}{n}\sum_{i=1}^n x_i^2 \;+\;\epsilon}
其中 \epsilon(如 1e^{-6})用于数值稳定。
- 归一化与缩放
\hat x_i= \frac{x_i}{\mathrm{RMS}(\mathbf{x})}\;\gamma_i
- 仅有一组可学习参数\gamma\in\mathbb{R}^n,通常不带 \beta。
对比 LayerNorm:
\hat x_i= \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}}\;\gamma_i + \beta_i
-
LayerNorm 既做了-\mu(去中心)又做了/\sqrt{\sigma^2};
-
RMSNorm 省略了-\mu和+\beta,只做一次遍历(平方→求均值→开根→除法→乘 γ)。
RMSNorm的应用
RMSNorm 是一种 “轻量级 LayerNorm”,通过只用 RMS 而省略偏移项,大幅降低归一化开销,在超大规模 Transformer 模型中已成为主流方案之一。
3.9 采样与输出——从 embedding 到 Token
3.9.1 输出转换
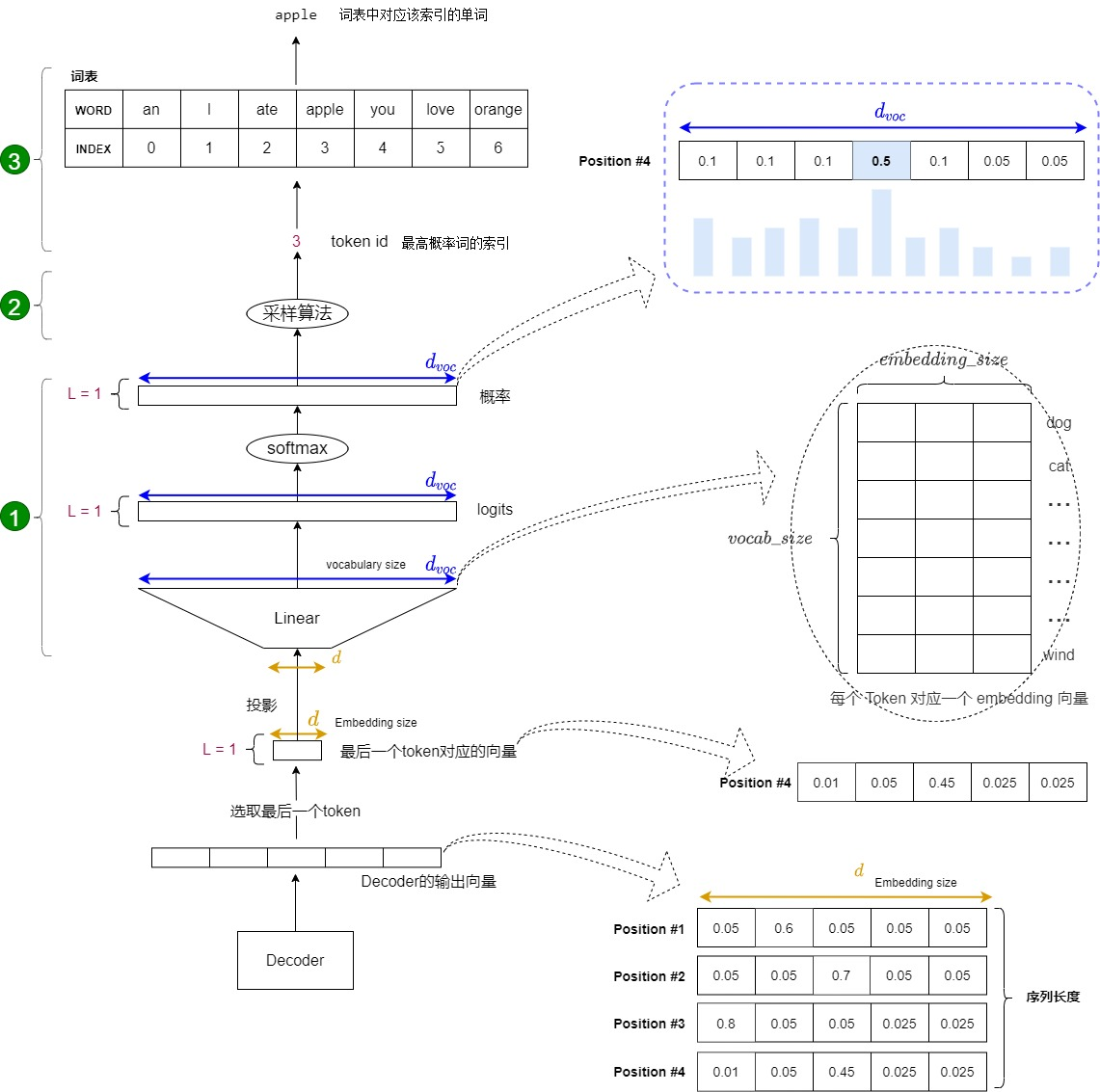
经过了 Encoder 和 Decoder 的全流程,我们获得了最终输出的向量矩阵,这个矩阵包含上文的 Token 序列以及预测的下一个 Token,在输出时,我们将最后输出的 Token 的 embedding 取出,然后与输出映射矩阵(Transformer 模型在输出映射时通常会使用与输入 Embedding 相同的权重矩阵(即权重共享),但也有模型这部分是独立的)进行线性变换,得到一个得分,即为每一个Token 预测一个打分(logit)
线性映射得到的打分(logits)将被输入到 Softmax 函数,Softmax 会将这些打分转换为概率分布,即对所有候选词的概率之和为 1。这样,对于每个时间步,模型就会输出在词表上每个词的生成概率,从而可以根据这些概率来决定要生成(或采样)哪一个词。
获得了每个词的概率之后,我们就可以通过采样算法来选择我们要输出的 Token 了
3.9.2 采样算法
Greedy Decoding(贪心解码)
在每一步,直接选择概率最大的 token 作为当前的生成结果,也就是 argmax 操作。
-
优点: 简单、高效,生成速度快。
-
缺点: 可能陷入局部最优,生成文本往往缺乏多样性和创意,可能重复或过于平淡。
Top-k Sampling
对于当前步骤的概率分布,先选出概率最高的 k 个 token,然后只在这 k 个 token 内按照它们的归一化概率进行随机采样。
设定 k 值(例如 10 或 50),可以有效剔除概率极低的候选项,保证生成结果在高概率区域内进行随机挑选,从而兼顾生成的合理性和多样性。
-
优点: 既避免了完全贪心选择带来的单一性,又控制了生成的范围,使生成的内容相对合理。
-
缺点: k 的取值需要调节,k 过小可能限制创造性,k 过大则可能引入噪声。
Top-p (Nucleus) Sampling
Top-p Sampling(也称 nucleus sampling)不是固定选择前 k 个 token,而是选择累积概率至少达到 p(如 0.9 或 0.95)的一组 token,然后在这组 token 中按照归一化概率进行采样。这种方法能根据实际概率分布动态确定候选集大小,既考虑了概率质量,又能灵活应对不同情况。
-
优点: 能够自适应地平衡生成文本的多样性和质量。
-
缺点: p 的设置影响较大,过高或过低都会造成生成结果偏向单一或噪声过多。
举例:
模型在某一步生成下一个 token 时,经过 softmax 得到以下概率分布,这里有 5 个候选 tokeng概率
(假设分别为 A、B、C、D、E):[ 0.4, 0.25, 0.15, 0.1, 0.1]
先将 token 按概率从大到小排序(这里已经是按降序排列的)。依次累加 token 的概率,直到累计概率达到设定的阈值p。假设我们设定p=0.8我们的候选集合就是 {A, B, C},因为在加入 A、B、C 后累计概率正好达到 0.80。如果加入 D 后累计概率就超过了设定的阈值(变为 0.90),那么我们就不会考虑 D 及之后的 token。然后我们的候选集合为 {A, B, C}。这时需要对这三个 token 的概率进行重新归一化,然后,从归一化后的分布中随机采样,获得最终生成的 token。
3.9.3 Temperature Scaling(温度调节)
Temperature Scaling(温度调节)是一种常用的技术,用于调整生成模型(如 Transformer)的 softmax 分布,从而控制采样过程的随机性和多样性。其核心思想是在计算 softmax 之前,对模型输出的 logits 除以一个温度参数T。具体来说,温度调节后的概率计算公式为:
p(i) = \frac{\exp\left(\frac{\text{logit}_i}{T}\right)}{\sum_j \exp\left(\frac{\text{logit}_j}{T}\right)}
-
温度T<1: 提高 logits 的差异,使得概率分布更尖锐,模型更倾向于采样高概率 token,生成结果确定性高,多样性较低。
-
温度T>1: 降低 logits 的差异,使得概率分布更平滑,降低高概率 token 的优势,允许更多候选 token 被采样,增加生成的随机性和多样性。
-
温度T=1: 则为原始 softmax 的标准形式,没有额外的平滑或强化效果。
四、Transformer 训练参数分析
4.1 Transformer 论文模型分析
以 Transformer 论文模型参数为例来说明各部分参数的典型大小:
-
模型维度(d_model):512
-
前馈网络维度(d_ff):2048
-
注意力头数(num_heads):8
-
词汇表大小(Vocab size):32000
-
Transformer block 数量:6
分模块分析
-
Embedding
-
Token Embedding 将输入 token 转换为向量表示,对应一个查找表(lookup table),每个 token 都有一个与之对应的向量。这部分参数在训练时会被更新。
-
大小:32000×512
-
参数量:约 16,384,000 个参数
-
-
Position Embedding (如果使用的是可训练的 positional embeddings),这部分也作为参数进行训练,用以捕捉序列中各个位置的信息。
-
大小:512×512
-
参数量:约 262,144 个参数
-
-
-
Encoder
-
Multi-Head Self-Attention
-
Query、Key 、Value 权重矩阵 W_Q、W_K、W_V
-
Query 矩阵: 大小 512×512,参数量大约 262,144
-
Key 矩阵: 同样大小 512×512,参数量大约 262,144
-
Value 矩阵: 同样大小 512×512,参数量大约 262,144
-
-
Attention 输出投影矩阵 ( W_O):对多个 attention head 的输出进行线性变换。
- 大小 512×512,参数量大约 262,144
-
每个矩阵通常还会有相应的 bias(有时部分实现中省略 bias,但大部分是可以训练的)。
-
-
前馈网络(Feed-Forward Network, FFN)
-
包含两个线性层,对应的权重矩阵(和偏置)通常记作W_1 和W_2。
-
每个全连接层大小:512×2048
-
参数量:约 1,048,576 个参数
-
-
激活函数(如 ReLU 或 GeLU)虽然本身没有参数,但线性层的参数会在训练中更新。
-
-
Layer Normalization
- 每个子层之后通常都会接一个 Layer Normalization 层,它包含两个可训练参数 Scale(gamma)和Shift(beta),大小可以忽略
-
-
Decoder
-
Masked Multi-Head Self-Attention
- 与编码器中的自注意力类似,包括 Query、Key、Value 权重矩阵及输出投影矩阵,以及相关 bias。参数量类似于 encoder 中的 Self-Attention
-
Encoder-Decoder Attention
- 这部分参数同样包括三个权重矩阵(用于将解码器输入和编码器输出分别映射到查询、键和值空间)以及输出投影矩阵。参数量类似于 encoder 中的 Self-Attention
-
前馈网络(Feed-Forward Network, FFN)
- 同编码器 FFN 部分,包括两个线性层的权重和偏置。
-
Layer Normalization
- 解码器每个子层(包括 Masked Self-Attention、Encoder-Decoder Attention 和 FFN 后)的归一化层,同样具有 gamma 和 beta 两个可训练参数。
-
-
输出层
-
线性投影加 Softmax
-
将解码器的最终输出映射到词汇表大小的维度,通常是通过一个线性层(权重矩阵和偏置)实现,之后会接 Softmax 层转换为概率分布。这个线性层的参数也是在训练过程中不断更新的。但有时会采用 weight tying 技术,即共享输入 Embedding 的参数。
-
如果不进行权重共享,则输出映射层参数量为:
-
大小:512×32000
-
参数量:约 16,384,000 个参数
-
-
总大小:60M 参数
4.2 GPT-3 模型分析
对于 GPT-3 的 175B 版本,论文中给出的主要架构参数大致为:
-
层数(Transformer Blocks): 96 层
-
模型维度(d_model): 12,288
-
前馈网络维度(d_ff): 4×d_model ≈ 49,152
-
词汇表大小(vocab size): 约 50,257(使用 Byte-Pair Encoding,BPE)
分模块分析
-
单个 Transformer 层参数估算
-
自注意力部分
-
Query、Key、Value 各自的权重矩阵大小均为:12,288×12,288 参数量约 151M(百万参数),所以三个矩阵共约453M
-
加上输出投影矩阵(大小相同),再增加 151M,总计604M
-
-
前馈网络(FFN)部分
- FFN 包含两个全连接层:第一个全连接层:参数量为 12,288×49,152, 约等于 604M,第二个全连接层:参数量为 12,288×49,152, 约等于 604M,两层合计为:1,208M
-
单层 Transformer Block 总参数,合计自注意力和 FFN 部分:604M+1,208M=1,812M(≈1.812Billion)
-
-
全部 Transformer 层参数
- 96 层的总参数大致为:96×1.812B≈174B(174Billion)
-
输入 Embedding:50,000×12,288≈614,400,000(≈0.61B)
-
输出映射层:通常采用权重共享策略,因此输出映射层不会增加额外的参数。
-
总计:将 Transformer 层和 Embedding 参数相加:174B+0.61B≈174.61B
可以看到,主要参数都集中在 Transformer Block 内
五、Transformer架构发展——百花齐放,百家争鸣
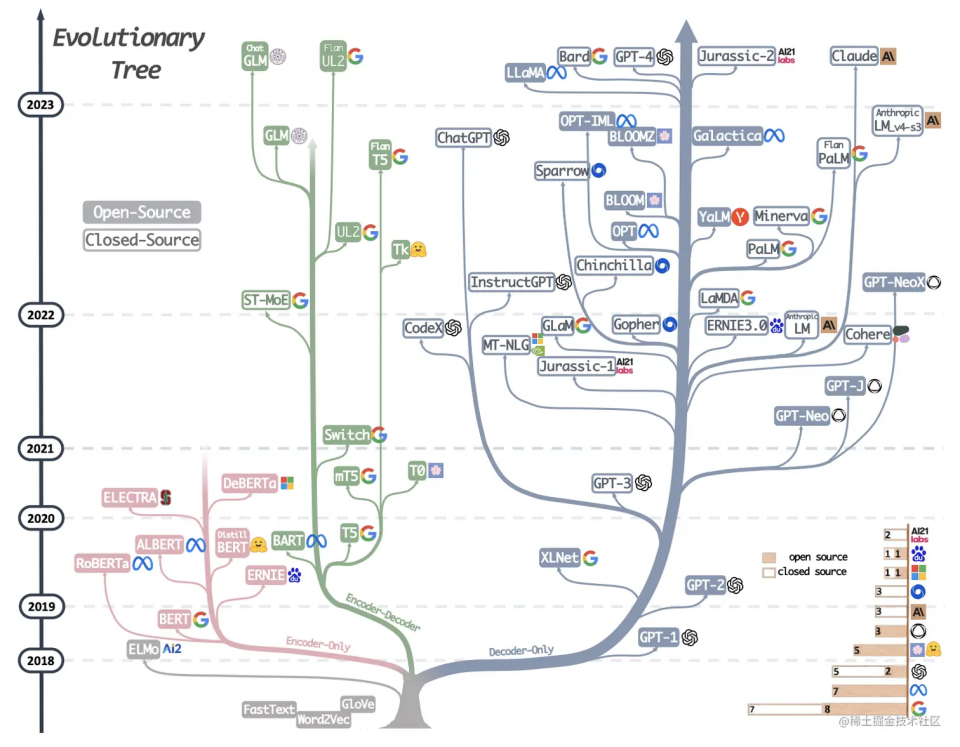
从论文发布以来,Transfomer 生态经历了大发展,各种模型架构层出不穷,大致可以分为三类:
-
Encoder-Decoder 模型架构
-
Encoder-Only 模型架构
-
Decoder-Only 模型架构
我们每种架构都分析一下
5.1 Encoder-Decoder——最初的 Transformer 架构
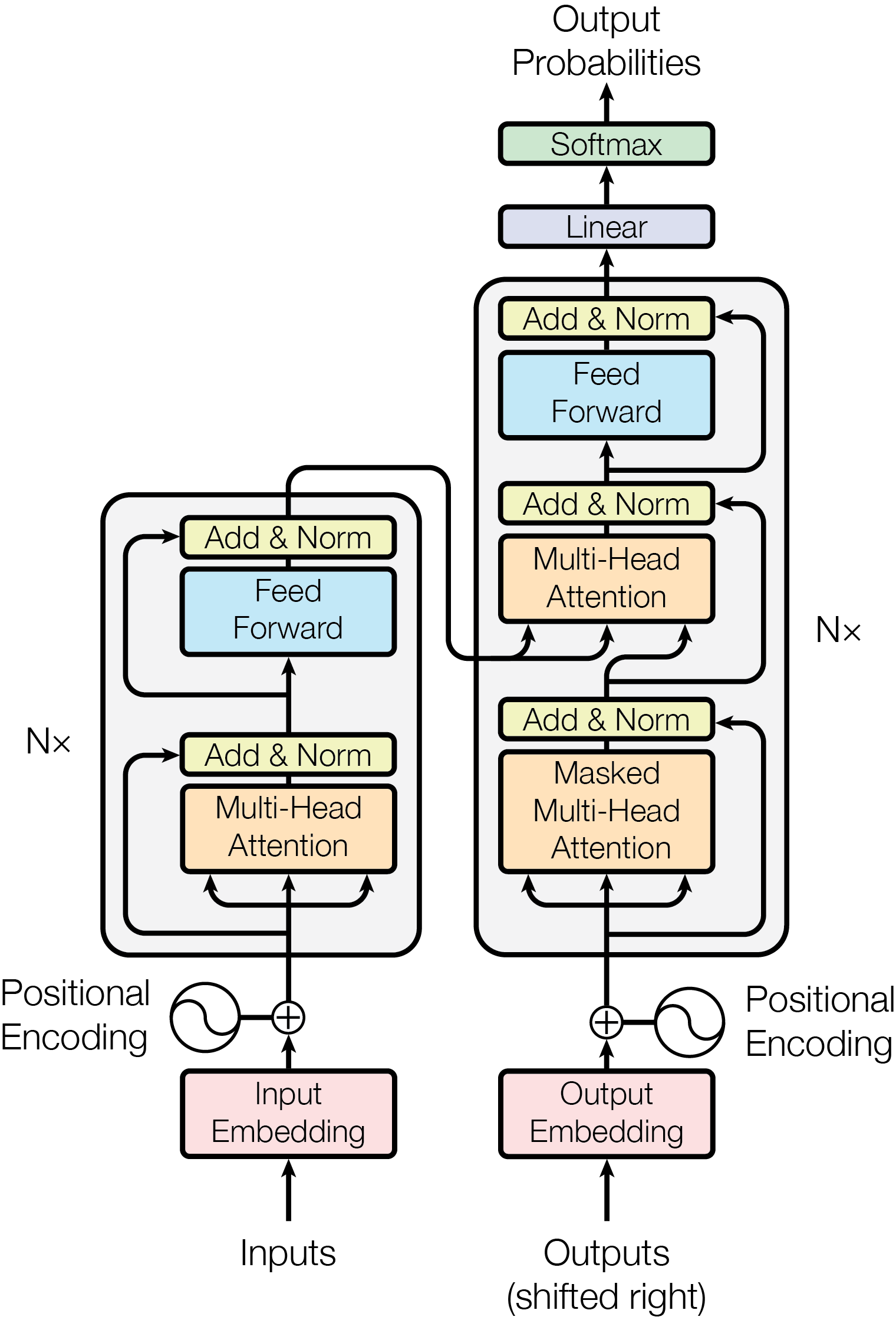
Encoder-decoder 模型(也称为序列到序列模型(sequence-to-sequence models))同时使用 Transformer 架构的编码器和解码器两个部分。在每个阶段,编码器的注意力层可以访问输入句子中的所有单词,而解码器的注意力层只能访问位于输入中将要预测单词前面的单词。
这些模型的预训练可以使用训练编码器或解码器模型的方式来完成,但通常会更加复杂。例如, T5 通过用单个掩码特殊词替换随机文本范围(可能包含多个词)进行预训练,然后目标是预测被遮盖单词原始的文本。
序列到序列模型最适合于围绕根据给定输入生成新句子的任务,如摘要、翻译或生成性问答。
代表模型
理解 Encoder-Decoder —— 以 T5 为例

T5 采用的是标准的序列到序列(Seq2Seq)架构,包含 Encoder 和 Decoder 两部分。
-
Encoder 部分T5 的 Encoder 使用的是全局的 self-attention,它允许输入序列中每个 token 与所有其他 token 进行交互,没有方向上的限制,因此可以看作是双向注意力。这种双向机制使得 Encoder 能够充分利用整个上下文信息,从而获得更丰富的语义表示。
-
Decoder 部分T5 的 Decoder 在自注意力部分采用了遮蔽机制(masked self-attention),确保在生成过程中,每个位置只能关注自己之前(或当前)生成的 token,从而保证生成时的自回归特性。此外,Decoder 还包含跨注意力层(cross-attention),用来关注 Encoder 的输出表示,这部分同样可以利用 Encoder 全局信息。
T5 的 Span Corruption:
T5 采用的是 span corruption 策略,在预训练前对输入文本做预处理。具体来说,T5 随机选取连续的一段 token(一个 span),并用一个或多个特殊的 sentinel token 替换这段文本。这样的处理会“破坏”输入,使得 Encoder 接收到的文本中部分内容被屏蔽掉,任务要求模型根据上下文来恢复缺失的信息。
5.2 Encoder-Only —— 专注文本理解
Encoder 模型仅使用 Transformer 的编码器部分。在每次计算过程中,注意力层都能访问整个句子的所有单词,这些模型通常具有“双向”(向前/向后)注意力,被称为自编码模型。
Encoder 的输入是整个句子(或文档)的 token 序列。每个 token 经过 Embedding 层和 Positional Encoding 后,形成一个包含位置信息的输入矩阵。这个矩阵一次性传入 Encoder,因此 Encoder 能够同时“看到”整个序列的所有 token。
自注意力机制允许每个 token 在计算自身的表示时,同时关注输入序列中的所有其他 token。具体来说,在每个 Encoder 层中,所有 token 的 Query、Key 和 Value 都是同时计算的,并通过矩阵运算得到注意力权重,因此每个 token 的输出表示都融合了全局上下文信息。这种机制使得 Encoder 可以并行地计算所有 token 的表示。
Transformer Encoder 的设计并不依赖于逐步递归或自回归生成。因为所有 token 之间的关系是通过矩阵运算一次性求解的,所以整个输出矩阵可以在一轮前向传播内全部计算出来。这与自回归生成模型(如 GPT 的 Decoder)不同,自回归模型需要根据前面的 token 逐步生成后续 token。
Encoder-only 模型(如 BERT)通常用于理解任务,而理解任务要求捕获整个输入序列的上下文关系。这种设计使得一次性输出整个 token embedding 矩阵变得非常高效和符合任务需求,因为整个序列都可以被同时编码,从而获得更全面的语义表达。
代表模型
理解 Encoder-Only —— 以 bert 为例
https://huggingface.co/blog/bert-101
bert 原始论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
bert 代码库:https://github.com/google-research/bert
BERT,是一个用于自然语言处理的机器学习(ML)模型。它由 Google AI Language 的研究人员于 2018 年开发,是一种处理 11+种最常见语言任务的多功能工具,例如情感分析和命名实体识别。
- 论文原文:
In this paper, we improve the fine-tuning based approaches by proposing BERT:BidirectionalEncoderRepresentations fromTransformers. BERT alleviates the previously mentioned unidirectionality constraint by using a “masked language model” (MLM) pre-training objective, inspired by the Cloze task Taylor (1953). The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-to-right language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pre-train a deep bidirectional Transformer. In addition to the masked language model, we also use a “next sentence prediction” task that jointly pre-trains text-pair representations.
在本文中,我们通过提出 BERT(Bidirectional Encoder Representations from Transformers)来改进基于微调的方法。BERT 通过使用“掩蔽语言模型”(MLM)预训练目标来缓解之前提到的单向性限制,这一目标受到了 Cloze 任务 Taylor (1953)的启发。掩蔽语言模型会随机掩蔽输入中的一些标记,目标是仅基于其上下文预测掩蔽词的原始词汇 ID。与从左至右的语言模型预训练不同,MLM 目标使得表示能够融合左右上下文,这允许我们预训练一个深度双向 Transformer。除了掩蔽语言模型外,我们还使用了一个“下一个句子预测”任务来共同预训练文本对表示。
BERT 的遮蔽策略(MLM):
在 BERT 中,模型的预训练任务是 Masked Language Modeling(MLM)。在这个过程中,随机选取输入中某些 token 用特殊的 [MASK] 标记替换,同时也有部分 token 保持原样或用随机词替换。这使得模型在预测被遮蔽 token 时只关注周围的上下文信息。
举例:
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Artificial Intelligence [MASK] take over the world.")
[{'score': 0.3182411789894104,
'sequence': 'artificial intelligence can take over the world.',
'token': 2064,
'token_str': 'can'},
{'score': 0.18299679458141327,
'sequence': 'artificial intelligence will take over the world.',
'token': 2097,
'token_str': 'will'},
{'score': 0.05600147321820259,
'sequence': 'artificial intelligence to take over the world.',
'token': 2000,
'token_str': 'to'},
{'score': 0.04519503191113472,
'sequence': 'artificial intelligences take over the world.',
'token': 2015,
'token_str': '##s'},
{'score': 0.045153118669986725,
'sequence': 'artificial intelligence would take over the world.',
'token': 2052,
'token_str': 'would'}]
5.3 Decoder-Only —— LLM时代的主流架构
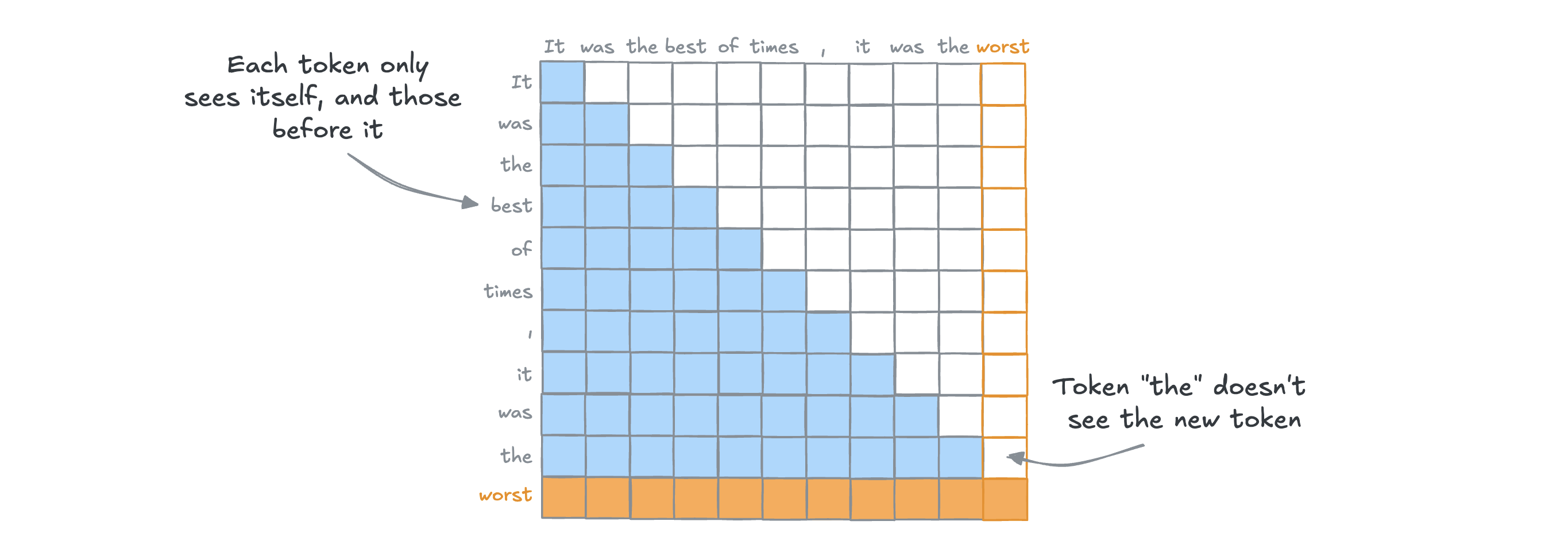
“Decoder”模型仅使用 Transformer 模型的解码器部分。在每个阶段,对于给定的单词,注意力层只能获取到句子中位于将要预测单词前面的单词。这些模型通常被称为自回归模型。
“Decoder”模型的预训练通常围绕预测句子中的下一个单词进行。
这些模型最适合处理文本生成的任务。
代表模型
理解 Decoder-Only——以 nano-gpt 为例进行可视化分析
5.4 为什么选择了 Decoder-Only?
结论摘抄自:为什么现在的LLM都是Decoder-only的架构?
-
**训练效率和工程实现:**笔者在10亿参数规模的模型上做了GPT和UniLM的对比实验,结果显示对于同样输入输出进行从零训练(Loss都是只对输出部分算,唯一的区别就是输入部分的注意力模式不同),UniLM相比GPT并无任何优势,甚至某些任务更差。假设这个结论具有代表性,那么我们就可以初步得到结论:输入部分的注意力改为双向不会带来收益,Encoder-Decoder架构的优势很可能只是源于参数翻倍。换句话说,在同等参数量、同等推理成本下,Decoder-only架构很可能是最优选择。
-
**理论计算:**Attention的矩阵因为低秩问题而带来表达能力的下降,具体分析可以参考《Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth》。而Decoder-only架构的Attention矩阵是一个下三角阵,注意三角阵的行列式等于它对角线元素之积,由于softmax的存在,对角线必然都是正数,所以它的行列式必然是正数,即Decoder-only架构的Attention矩阵一定是满秩的!满秩意味着理论上有更强的表达能力,也就是说,Decoder-only架构的Attention矩阵在理论上具有更强的表达能力,改为双向注意力反而会变得不足。
综上所述:LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。


